Java 项目在使用 Aerospike 缓存时,会有 Error Code 8 : Server memory error 报错,导致缓存数据无法正常写入。
一、问题背景
在 Java 客户端出现 Error Code 8 : Server memory error 报错:
com.aerospike.client.AerospikeClient : Error Code 8: Server memory error
com.aerospike.client.AerospikeException: Error Code 8: Server memory error
at com.aerospike.client.command.WriteCommand.parseResult(WriteCommand.java:54)
at com.aerospike.client.command.SyncCommand.execute(SyncCommand.java:84)
at com.aerospike.client.Aerospike.put(AerospikeClient.java:378)
在 AMC 监控中发现 Avail 过低:
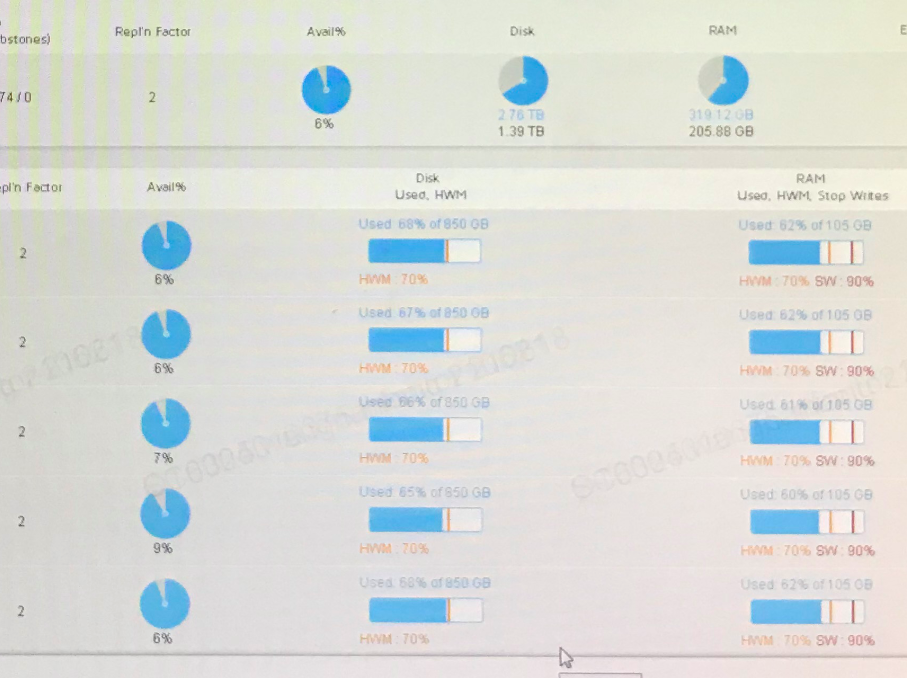
二、Error Code 8 出现原因
- 当 stop_write 触发时,出现
- memory - stop-write-pct ,即当内存达到 SW(stop-write)时,默认 90%。
- disk - min-avail-pct,当为命名空间配置的 devices 之一 (或 pmem 文件) 上的 device_available_pct 低于此指定百分比时,禁止写入(删除,副本写入和迁移写入除外),默认 5%。
- 如果不能再分配内存(但 stop_writes 通常应该先命中),也可能发生。
- 命名空间将不再能够接受写入请求。
三、如何恢复连续的空闲块,即可用百分比(available percent)
3.1 什么是 available percent?
可用百分比 (device_available_pct)是一个关键的 Aerospike 指标,用于测量最小连续可用磁盘空间(以块大小为单位 write-block-size)跨命名空间中的所有设备,即:
Avail_pct = min(命名空间中所有磁盘的 contig_disk)
3.2 当命名空间的可用百分比很低时会发生什么?
从应用程序的角度来看,可用百分比低的主要表现是,当访问某个节点的名称空间在其某个设备上没有足够的连续空闲磁盘空间时,写入将会失败。在这种情况下返回给客户端的错误是:
com.aerospike.client.AerospikeException: Error Code 8: Server memory error
The server will log the following WARNING:
WARNING (rw): (write.c:770) {namespaceid}: write_master: drives full
更准确地说,当 device_available_pct 低于任何命名空间设备上的 min-avail-pct 配置阈值(默认为 5%)时,应用程序写入将开始失败。
3.3 最常见的情况和补救措施
3.3.1 容量过度使用(或磁盘真的“已满”)
如果由于每个块的使用百分比高于容量是 defrag-lwm-pct 阈值,而没有符合碎片整理条件的块,则会发生这种情况。
验证这种情况,可以检查每个设备的设备日志行:
INFO (drv_ssd): (drv_ssd.c:2115) {namespaceid} /dev/xvdb: used-bytes 1626239616 free-wblocks 28505 write-q 0 write (8203,23.0) defrag-q 0 defrag-read (7981,21.7) defrag-write (1490,3.0) shadow-write-q 0 tomb-raider-read (1615,59.6)
- 如果 defrag-q 较低或为 0,并且碎片整理写入速率也较低或为 0.0,则表明没有符合碎片整理条件的块。
- 如果磁盘使用百分比 ( device_used_bytes / device_total_bytes x 100 ) 大于配置 defrag-lwm-pct,磁盘高于正常碎片整理的安全操作阈值。
以下是可能的补救措施:
- 删除记录(例如使用 truncate 命令)。
- 如果可接受,可以对数据进行驱逐。相关配置参数如下:
- evict-tenths-pct:(增加)每次逐出的最大数据量,默认 5,逐出总数据的千分之五,如果配置为 100,则逐出数据的百分之十。
- high-water-disk-pct:(减少)磁盘高水位线,当磁盘使用率大于等于此值,将进行磁盘数据逐出,默认值 60。
- high-water-memory-pct:(减少)内存高水位线,当内存使用率大于等于此值,将进行内存数据逐出,默认值 50。(关于逐出,默认逐出最接近过期的数据)
- nsup-delete-sleep:(减少)在版本4.5.1中已删除,因为nsup不再用于 delete transactions 。生成 delete transactions 之间要休眠的微秒数。
- nsup-period:(减少)主 expiration/eviction 线程(称为 nsup, namespace supervisor)唤醒以处理命名空间的时间间隔。 nsup-period 0 的默认值禁用命名空间的 namespace supervisor 。默认情况下,该值以秒为单位。您还可以用分钟,小时或天为单位设置此值,其表示法为 1m or 1h or 1d 。如果在 nsup 工作时将其 nsup-period 动态设置为 0,则 nsup 将在完成其当前周期,然后进入休眠状态。确保时间在集群中的各个节点之间是同步的。对于 Aerospike 4.5.1 或更高版本,对于启用 nsup (即 nsup-period 不为零)的每个命名空间,如果集群始终偏斜超过 40s , 写入将被挂起。确保已安装,配置并正常运行网络时间协议(NTP)或其他时间同步机制。 在Aerospike 4.9版之前,默认值为120。 从 Aerospike 4.9 版本开始,如果 nsup-period 为 0(默认值)但 default-ttl 为非零,则服务器将不会启动,除非 allow-ttl-without-nsup 设置为 true。
- 添加额外容量(每个命名空间有更多节点或更多设备)。
- 逐渐增加 defrag-lwm-pct 临界点。鉴于这将导致非线性写入放大增加,请监控性能影响。
3.3.2 尺寸不匹配的设备
鉴于整体可用百分比的定义 – Avail_pct = min(命名空间中所有磁盘的 contig_disk) ,当有一个非常小的尺寸的设备时,如果该设备触发 stop_writes,即使其他设备拥有很大的空闲空间,依旧会出现这种情况。
检查用于使用字节和空闲 wblock 的设备特定日志行应该可以快速确定是否是这种情况。当然,验证每个设备或分区的物理大小也会产生信息。
3.3.3 碎片整理没有跟上
在某些情况下,有块需要进行碎片整理,但碎片整理跟不上。将碎片整理率与每个设备日志行上的写入率进行比较。碎片整理队列 (defrag-q) 不断增加是碎片整理没有跟上的迹象:
INFO (drv_ssd): (drv_ssd.c:2143) {namespaceid} /dev/nvme0n1: used-bytes 1182271397376 free-wblocks 1212517 write-q 0 write (1304972843,497.1) defrag-q 6743042 defrag-read (1309698931,609.4) defrag-write (639136010,191.8)
在这种情况下,可以增加碎片整理线程的速度。默认情况下,碎片整理线程在每次块读取之间休眠 1000 微秒。这可以通过 defrag-sleep 配置选项。建议逐渐减小该值,并观察对存储子系统(例如使用iostat)和应用程序性能的潜在影响。以下命令将使读取要进行碎片整理的块的默认速度加倍。
$ asinfo -v "set-config:context=namespace;id=<namespace name>;defrag-sleep=500"
3.3.4 过大的 post-write-queue
post-write-queue中的块(默认为每个设备 256 个块)不适合进行碎片整理。对于具有小设备和大 write-block-size的命名空间,post-write-queue可能是设备本身的重要部分,甚至更大。这显然会很快导致低的可用百分比情况。
例如,在大小为 4GiB 的设备上, post-write-queue 512 和 write-block-size 8M ,对于该命名空间,此时队列占用的总大小将是 512 * 8MiB = 4096 MiB = 4GiB,并且没有进行碎片整理。
3.3.5 碎片整理的块没有及时释放(不常见)
从 3.16.0.1 版本开始,碎片整理的块在新块上重写的数据被刷新之前不会被释放:
- [AER-5776] - (STORAGE) 在清除碎片整理的所有数据之前不要释放碎片整理的写入块。
在某些极端情况下,通常在记录非常少且持续更新的设备上,可能会因为碎片整理线程正在写入的新块需要很长时间才能填充大量释放的块。这在 4.3.1.5 版中得到解决: - [AER-5950] - (STORAGE)当碎片整理负载极低时,定期刷新碎片整理缓冲区以释放源写入块。
四、如何从可用百分比 0 中恢复
4.1 调整碎片整理速度和阈值
如果碎片整理没有跟上,可以使用以下 2 个设置调整碎片整理速度和密度:
$ asinfo -v "set-config:context=namespace;id=<namespace name>;defrag-lwm-pct=50"
$ asinfo -v "set-config:context=namespace;id=<namespace name>;defrag-sleep=500"
4.2 增加对过期数据的驱逐
可能还需要增加驱逐以允许删除更多记录并允许更多块有资格进行碎片整理。
驱逐可以通过设置进行调整:
- evict-tenths-pct(增加)
- high-water-disk-pct(减少)
- high-water-memory-pct(减少)
- nsup-delete-sleep (减少)
- nsup-period(减少)
4.3 通过添加新节点来增加容量
添加新节点以增加容量很简单。如果您的系统磁盘或分区上的可用连续空间已用完,则添加新节点允许当前节点卸载 1/(new cluster size)数据。这种方法的成功几率与集群的大小成反比。您可以通过停止应用程序层生成的新写入来进一步提高成功的机会。
4.4 停止节点上的服务和零碎片持久存储
如果您使用复制因子 1 运行,则“dd”方法通常是不可接受的,因为此方法需要从命名空间中删除 wblock,这会导致复制因子 1 的数据丢失。
复制因子 2 可以从数据丢失中正常恢复,因为当节点恢复时,删除的数据将通过迁移(重新平衡)重新填充回节点。这种方法需要冷重启(它将是空的)并且是唯一可以保证一次性释放 wblock 的方法。
这假设集群中的其他节点没有用完 avail pct 并且可以处理迁移。
DD 命令可用于将驱动器归零 :
`sudo dd if=/dev/zero of=/dev/DEVICE bs =1M
使用 blkdiscard
sudo blkdiscard /dev/<INSERT DEVICE NAME HERE>
删除持久存储文件
sudo rm <Aerospike persistent storage file>
4.5 Cold-Start-Evict-TTL 方法
cold-start-evict-ttl告诉系统在冷启动期间将忽略 TTL 低于特定值的任何内容。这通常用于加速冷启动。当你知道你的驱逐深度很深时。要运行您的驱逐深度:
$ asinfo -v "hist-dump:ns=<namespace name>;hist=ttl"
value is <namespace name:ttl=100,51840,0,0,0,0,0,0,0,0,0,0,0, \
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, \
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,920023,10263488, \
20000052,20319938,23861472,20052298,21612051,22163298, \
24370589,34911006,27048399,29558473,27697235,21049529, \
20300346,17539324,17954128,16932493,16265998,20131370, \
15997368,18030184,17260295,16613023,21100184,18003700, \
20814926,19660860,18829521,23601739,17515442,21490671, \
19797821,19861895,24694092,11354573,14945634,14806583, \
17064793,37144797;
此直方图中的第一个数字表示此直方图包含多少个桶,第二个值是每个桶的宽度(以秒为单位),其余 100 个值是落在各种 ttl 范围内的记录数,最后一个是更大的记录比(100 * 宽度)。
对于这个特定的直方图,我们可以看到每个桶是 51840 秒,14.4 小时,并且在宽度和第一个填充值之间有 60 个零。这意味着当前的驱逐深度是 (60 * 51840)。
我们必须增加驱逐深度才能使这种方法起作用,成功的几率与您使用冷启动 evict-ttl 增加驱逐深度的量成正比。
五、后记
-
在碎片整理速度成为问题的情况下,将 SSD 分区为多个分区可能是有益的。您将失去少量的存储空间,但会获得碎片整理线程。物理 SSD 及其分区都是"device"。每个设备有一个碎片整理线程。
-
在存储充满非过期对象 (TTL=0) 的情况下,碎片整理和逐出解决方案将无济于事。在这种情况下,我们建议与实施行方商议数据的最大保留时间,尽量不要设置default-ttl为零,防止数据无法逐出,并通过添加额外的存储或节点来增加容量。
-
不管您使用的是 SDD or HDD,如果可以直接使用挂载设备,请直接配置挂载设备,这将比配置file使用文件句柄的方式效率更高。
-
如果要保证应用可用,可暂时增加 max-write-cache ,不过这个只能暂时保证数据写入,如果写入速度一直很高,依旧会出现上述问题。
asinfo -v 'set-config:context=namespace;id=namespaceName;max-write-cache=128M'