有效沟通取决于使用共同的语言。这一观点对于人类、动物以及计算机而言都是适用的。当一种语言用于一组行为时,需要使用一种协议。根据《新牛津美国辞典》,对协议的第一定义是:
国家事务或外交场合的正式程序或规则系统。
我们每天执行很多协议:询问和回答问题、谈判商业交易、协同工作等。计算机也会执行备种协议。一系列相关协议的集合称为一个协议族。指定一个协议族中的备种协议之间的相互关系并划分需要完成的任务的设计,称为协议族的体系结构或参考模型。 TCP/IP是一个实现Internet体系结构的协议族,它来源于 ARPANET 参考模型(ARM) [RFCO871]。 ARM 受到了早期分组交换工作的影响,这些工作包括美国的 Paul Baran [B64] 和 Leonard Kleiurock [K64、英国的Donald Davies [DBSW66] 、法国的Louis Pouzin [P73] 。虽然数年之后制定了其他协议体系结构(例如, ISO协议体系结构[Z80]、 Xerox的XNS [X85] 和 IBM 的 SNA [I96] ),但TCP/IP已成为最流行的协议族。这里有几本有趣的书籍,它们关注计算机通信的历史和Internet的发展,例如 [PO7] 和 [WO2 ]。
值得一提的是,TCP/IP体系结构来源于实际工作,用于满足多种不同的分组交换计算机网络的互联需求 [CK74]。这由一组网关(后来称为路由器)来实现,网关可以在互不兼容的网络之间提供翻译功能。随着越来越多的提供备种服务的节点投人使用,由此产生的“串联”网络或多类型网络(catenet)——后来称为互联网络(internetwork)将更加有用。在协议体系结构全面发展之前的几年,有人已经设想了全球性网络可能提供的服务类型。例如,在 1968 年, J. C. R. Licklider和Bob Taylor已预见到支持“超级通信”的全球性互联通信网络的潜在用途 [LT68] :
今天的在线社区彼此在功能和地理位置上是分离的。每个成员只能看到以自己社区为中心的设施的处理、存储和软件能力等功能。但是,现在的变化趋势是分离的社区之间的互联,从而将它们变成我们所说的超级社区。互联使所有社区中的所有成员能访问整个超级社区中的程序和数据资源……这个变化将形成一个由很多网络组成的不稳定网络,该网络无论在内容还是配置上都在变化。
因此,支撑 ARPANET 和后来的 Internet 的全球网络概念,很明显是针对我们今天使用的很多服务类型而设计的。但是,要做到这点是不容易的。其成功来源于对设计和实现的重视,创新型用户和开发人员,以及提供足够多的资源,促使概念转化为原型系统,并最终转化为商业化的网络产品。
本章是对 Internet 体系结构和 TCP/IP 协议族的概述,提供了一些历史知识,并为后续章节建立足够的背景支撑。体系结构(协议和物理)实际上是一组设计决策,涉及支持哪些特点和在哪里实现这些特点。设计一个体系结构更多的是艺术而不是科学,但我们将讨论体系结构中随着时间推移被认为可行的那些特点,网络体系结构的主题已在Day [D08] 中被广泛讨论,它是这方面的几种方案之一。
1.1 体系结构原则
TCP/IP 协议族允许计算机、智能手机和嵌入式设备之间通信,它们可以采用备种尺寸、来自不同计算机生产商和运行备种软件。在 21 世纪到来之际,这已成为现代通信、娱乐和商务活动的必要需求。 TCP/IP 确实是一个 开放的系统,协议族定义和很多实现是公开的,收费很少或根本不收费。它构成全球因特网(Internet)的基础(因特网是一个拥有遍布全球的大约 20 亿用户(2010 年,占全球人口的 30%)的广域网)。尽管很多人认为因特网和万维网是可互换的术语,但我们通常认为因特网在计算机之间提供了消息通信能力,而万维网是一种使用因特网来通信的具体应用。在 20 世纪 90 年代早期,万维网恐怕是最重要的因特网应用,并使因特网技术得到全世界的重视。
Internet 体系结构在几个目标的指导下建立。在 [C88] 中, Clark 描述首要目标是“发展一种重复利用已有的互联网络的技术” 。这句话的本质是 Internet 体系结构应将多种网络互联起来,并在互联的网络上同时运行多个应用。基于这个首要目标, Clark 提供了以下的二级目标列表:
- Internet 通信在网络或网关失效时必须能持续。
- Internet 必须支持多种类型的通信服务。
- Internet 体系结构必须兼容多种网络。
- Internet 体系结构必须允许对其资源的分布式管理。
- Internet 体系结构必须是经济有效的。
- Internet 体系结构必须允许低能力主机的连接。
- Internet 中使用的资源必须是可统计的。
上面列出的很多目标将被最终的设计决策所采纳。但是,在制定这些体系结构原则时,这些原则影响到设计者所做的选择,最后少数几种设计方案脱颖而出。我们将提到其中几种重要方案及其结果。
1.1.1 分组、连接和数据报
直到 20 世纪 60 年代,网络的概念主要是基于电话网络。它是针对在一次通话中连接双方通话而设计的。一次通话通常要在通话双方之间建立一条连接。建立一个连接意味着,在一次通话过程中,通话双方之间需要建立一条线路(最初是一条物理电路)。当一次通话结束时,这条连接被释放,允许这条线路用于其他用户通话。通话时间和连接端身份用于用户计费。当一次连接建立后,它为用户提供一定数量的带宽或容量,以便传输信息(通常是语音)。电话网从最初的模拟网络演变到数字网络,这样极大地提高了自身的可靠性和性能。在线路一端输入的数据,沿着某些预先建立的经过网络交换机的路径,通常具有某个时
间(延迟)上限,在线路另一端以一种可预测方式出现。这样,在用户需要且线路可用的情况下,可以提供可预测的服务。线路是一条通过网络的路径,它为一次通话过程而保留,即使在并不繁忙的情况下。关于电话网络的常识是:在一次通话期间,即使我们没有说任何话,也要为这段时间而付费。
20世纪60年代出现的一个重要概念(如 [B64] 中)是分组交换思想。在分组交换中,包含一定字节数的数字信息“块” (分组)独立通过网络。来自不同来源或发送方的块可以组合,而且以后可以分解,这称为“(多路)复用”。这些块在到达目的地的过程中,需要在交换设备之间传输,并且路径可以改变。这样做有两个潜在的优点: 网络更有弹性(设计者不用担心网络受到物理攻击),基于统计复用可更好地利用网络链路和交换设备。
当一台分组交换机接收到分组时,它们通常存储在缓存或队列中,并通过先到达先服务(FCFS)的方式处理。这是最简单的分组处理调度方式,又称为先进先出(FIFO)。 FIFO 缓冲区管理和按需调度很容易结合起来实现统计复用,它是 Internet 中用来处理不同来源的混合流量的主要方法。在统计复用中,流量基于到达的统计或时间模式而混合在一起。这种多路复用是简单而有效的,因为如果网络带宽被使用和有流量通过,那么网络中的每个瓶颈或阻塞点将会繁忙(高利用率)。这种方法的缺点是可预测性有限,通过某些特定应用的性能可看出,它依赖于对共享网络的其他应用的统计。统计复用就像是一条高速公路,车辆可以变换车道,但是最终会分散在备处,任何点的收缩都可能造成道路繁忙。
某些替代性的技术,例如时分复用(TDM)和静态复用,通常在每个连接上为数据保留一定量的时间或其他资源。虽然这种技术可能具有更好的可预测性,可用于支持恒定比特率的电话通话功能,但它可能无法充分利用网络带宽,这是由于保留的带宽可能未使用。注意,当电路是通过 TDM 技术来实现时,虚电路(VC)会表现出很多电路行为,但是不依赖于物理的电路交换机,而通过顶层的面向连接的分组来实现。这是流行的 x.25 协议的基础,该技术直到 20 世纪 90 年代初才开始被帧中继大规模取代,并最终被数字用户线(DSL)技术和支持Internet连接的电缆调制解调器所取代(见第 3 章)。
对于虚电路抽象和面向连接的分组网络(例如 x.25 ),需要在每个交换机中为每个连接存储一些信息或状态。原因是每个分组只携带少量的额外信息,以提供到某个状态表的索引。例如,在 x.25 中, 12 位的逻辑信道标识符(LCI)或逻辑信道号(LCN)被用于这个目的。在每台交换机中, LCI 或 LCN 和交换机中的每个流状态相结合,以决定分组交换路径中的下一台交换机。在使用信令协议在一条虚电路上交换数据之前,每个流状态已经建立,该协议支持连接建立、清除和状态信息。因此,这种网络称为面向连接的。
无论是建立在线路还是交换的基础上,面向连接的网络是多年来最流行的联网方式。在 20 世纪 60 年代后期,数据报作为另一种可选方案而得到发展。数据报起源于 CYCLADES [P73] 系统,它是一个特定类型的分组,有关来源和最终目的地的所有识别信息都位于分组中(而不是分组交换机中)。虽然这通常需要较大的数据包,但不需要在交换机中维护连接状态,它可用于建立一个无连接的网络,并且没必要使用复杂的信令协议。数据报很快被早期的 Internet 设计者所接受,这个决定对协议族其他部分有深远影响。
另一个相关的概念是消息边界或记录标记。如图 1-1 所示,当一个应用将多个信息块发送到网络中,这些信息块可能被通信协议保留,也可能不被通信协议保留。大多数数据报协议保存消息边界。这样设计是很自然的,因为数据报本身有一个开始和结束。但是,在电路交换或虚电路网络中,一个应用程序可能需要发送几块数据,接收程序将所有数据作为一个块或多个块来读取。这些类型的协议不保留消息边界。在底层协议不保留消息边界,而应用程序需要它的情况下,应用程序必须自已来提供这个功能。
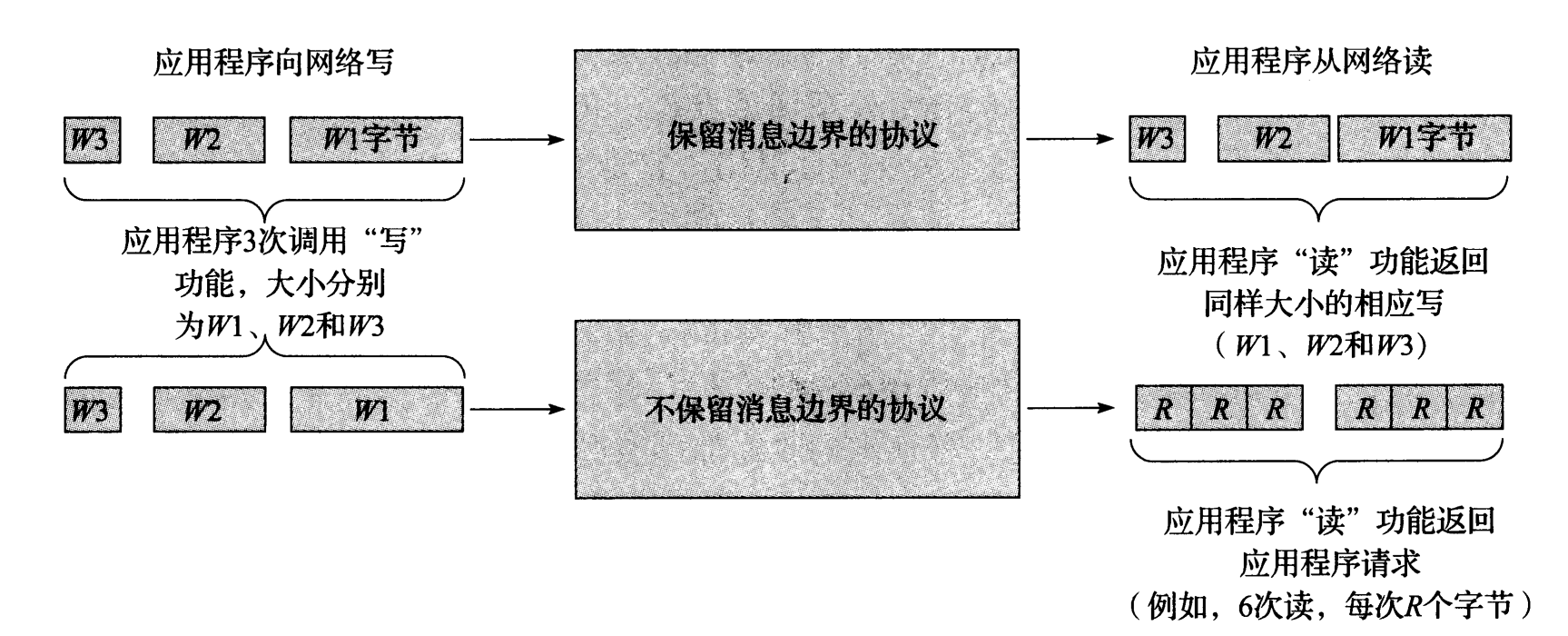
图 1-1 应用程序将协议携带的数据写人消息。消息边界是两次写入之间的位置或字节偏移量。保留消息边界的协议由接收方给出发送方的消息边界。不保留消息边界的协议(例如,像 TCP 这样的流协议)忽略这类信息,并使它在接收方无效。这样做的结果是,如果这个功能是必需的,应用程序需要自已实现发送方的消息边界
1.1.2 端到端论点和命运共享
当我们设计一个大的系统(例如操作系统或协议族)时,随之而来的问题通常是在什么位置实现某个功能。影响 TCP/IP 协议族设计的一个重要原则称为端到端论点 [SRC84] :
只有在通信系统端角度的应用知识的帮助下,才能完全和正确地实现问题中提到的功能。因此,作为通信自身的一个特点,不可能提供有疑问的功能。 (有时,通信系统提供的一个功能不完整的版本可能用于提高性能。)
在第一次阅读时,这种观点看起来似乎相当直观,它可能对通信系统设计产生深远影响。它认为只有涉及通信系统的应用程序或最终用户,其正确性和完整性才可能得到实现。即使为正确实现应用程序做了努力,其功能可能注定不会很完善。总之,这个原则认为重要功能(例如差错控制、加密、交付确认)通常不会在大型系统的低层(见 1.2.1 节)实现。但是,低层可以提供方便端系统工作的功能,并最终可能改善性能。这种观点表明低层功能不应以完美为目标,这是因为对应用程序需求做出完美推测是不可能的。
端到端论点倾向于支持一种使用“哑”网络和连接到网络的“智能”系统的设计方案。这是我们在 TCP/IP 设计中所看到的,很多功能(例如,保证数据不丢失、发送方控制发送速率)在端主机的应用程序中实现。选择哪些功能在同一计算机、网络或软件栈中实现,这是另一个称为命运共享的相关原则 [C88] 。
命运共享建议将所有必要的状态放在通信端点,这些状态用于维护一个活动的通信关联(例如虚拟连接)。由于这个原因,导致通信失效的情况也会导致一个或更多端点失效,这样显然会导致整个通信的失败。命运共享是一种通过虚拟连接(例如,由 TCP 实现)维持活动的设计理念,即便网络连接在一段时间内失效。命运共享也支持一种“带智能终端主机的哑网络”模型,当前 Internet 中的矛盾是:哪些功能在网络中实现,哪些功能不在网络中实现。
1.1.3 差错控制和流量控制
在网络中存在数据损坏或丢失的情况。这可能出于各种原因,例如硬件间题、数据传输中被修改、在无线网络中超出范围,以及其他因素。对这种错误的处理称为差错控制,它可以在构成网络基础设施的系统、连接到网络的系统或其他组合中实现。显然,端到端论点和命运共享建议在应用程序附近或内部实现差错控制。
通常,在只有少数位出错的情况下,我们关注的是,当数据已被接收或正在传输过程中,有些数学代码可用于检测和修复这种位差错 [LC04] 。这个任务通常在网络中执行。当更多严重损坏发生在分组网络时,整个分组通常被重新发送或重新传输。在线路交换或虚电路交换网络(例如 X.25 )中,重新传输通常在网络内部进行。这对那些顺序要求严格和无差错交付的应用是有用的,但有些应用不需要这种功能或不希望为数据可靠交付而付出代价(例如连接建立和重新传输延迟)。一个可靠的文件传输应用并不关心交付的文件数据块的顺序,最终将所有块无差错地交付并接原来顺序重新组合即可。
针对网络中可靠、按顺序交付的实现开销,帧中继和 Internet 协议采用一种称为尽力而为交付的服务。在尽力而为的交付中,网络不会花费很大努力来确保数据在没有差错或缺陷的情况下交付。某些差错通常用差错检测码或校验和来检测,例如那些可能影响一个数据报定向的差错,当检测到这种差错时,出错的数据报仅被丢弃而没有进一步行动。
如果尽力而为的交付成功,发送方能以超过接收方处理能力的速度生成信息。在尽力而为的 IP 网络中,降低发送方的发送速度可通过流量控制机制实现,它在网络外部或通信系统高层中运行。注意, TCP 会处理这种问题,我们将在第 15 章和第 16 章中详细讨论。这与端到端论点一致:TCP 在端主机中实现速率控制。它也与命运共享一致:这种方案在网络基础设施中有些单元失效的情况下,不会影响网络设备的通信能力(只要有些通信路径仍然可用)。
1.2 设计和实现
虽然建议用一个特定方法实现一个协议体系结构,但是这通常不是强制的。因此,我们对协议体系结构和实现体系结构加以区分,实现体系结构定义了协议体系结构中的概念如何用于软件形式的实现中。
很多负责实现 ARPANET 协议的人员都熟悉操作系统的软件结构,一篇有影响力的论文描述的“ THE”多编程系统 [D68] ,主张使用一种层次结构的处理方式,以检查一个大型软件实现逻辑的稳健性和正确性。最终,这有助于形成一种网络协议的设计理念,它涉及实现(和设计)的多个层次。这种方案现在称为分层,它是实现协议族的常用方案。
1.2.1 分层
通过分层,每层只负责通信的一个方面。采用多层是有益的,这是因为分层设计允许开发人员分别实现系统的不同部分,它们通常由在不同领域的专业人员完成。最常提到的协议分层概念基于一个称为开放系统互连标准(OSI)的模型 [Z80],该模型是由国际标准化组织(ISO)定义的。图 1-2 显示了标准的 OSI 层次,包括它们的名称、编号和若干例子。Internet 的分层模型比较简单,我们将在 1.3 节中介绍。
尽管 OSI 模型建议的 7 个逻辑层在协议体系结构的模块化实现中是可取的,但是通常认为 TCP/IP 体系结构包含 5 层。在 20 世纪 70 年代初,已有很多关于 OSI 模型的相对优势和不足,以及 ARPANET 模型优于它的争论。公平地说,尽管 TCP/IP 最终取得“胜利”,但来自 ISO 协议族(由 ISO 遵循 OSI 模型进行标准化)的一些思想,甚至整个协议已被用于 TCP/IP 中(例如 IS-IS [RFC3787] )。
如图1-2的简要介绍,每层都有不同任务。自下而上,物理层定义了一种通过某种通信介质(例如一条电话线或光纤电缆)传输数字信息的方法。以太网和无线局域网(Wi-Fi)标准的一部分也在这层,但我们不打算在本书中深人介绍。链路层或数据链路层包含为共享相同介质的邻居建立连接的协议或方法。有些链路层网络(例如 DSL )只连接两个邻居。当超过一个邻居可以访问共享网络时,这个网络称为多接入网络。Wi-Fi 和以太网是这种多接入链路层网络的例子,特定协议用于协调多个站在任何时间访问共享介质。我们将在第3章中讨论。
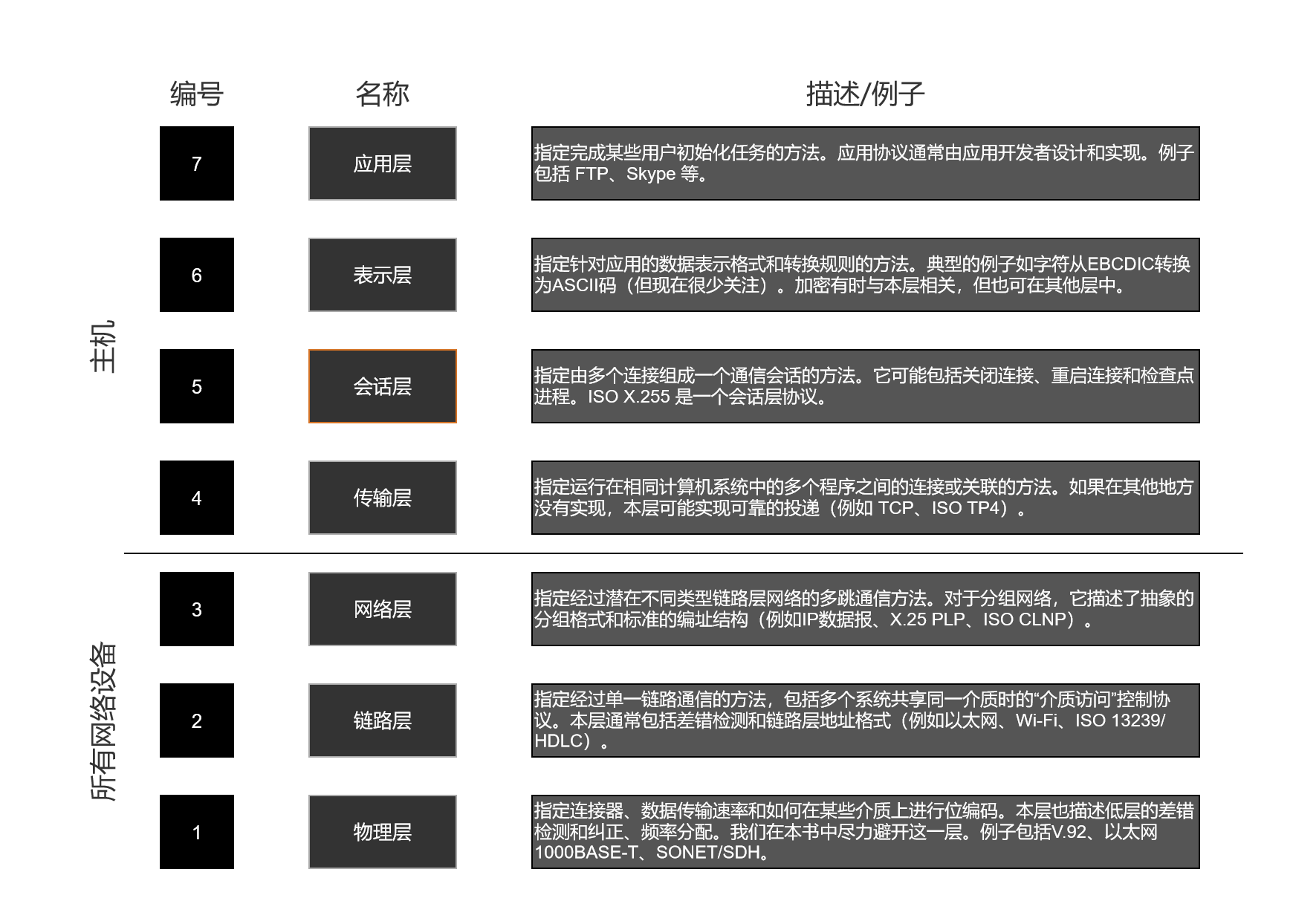
图 1-2 ISO 定义的标准 7 层 OSI 模型。每个网络设备(至少从理论上)并不需要实现所有协议。OSI 的术语和层数被广泛使用
在层次结构中,我们对网络层或互联网络层最有兴趣。对于分组网络(例如 TCP/IP ),它提供了一种可互操作的分组格式,可通过不同类型的链路层网络来连接。本层也包括针对主机的地址方案和用于决定将分组从一台主机发送到另一台主机的路由算法。对于上述 3 层,我们发现协议(至少在理论上)仅实现在端主机中,这也包括传输层。我们对传输层也有很大兴趣,它提供了一个会话之间的数据流,而且可能相当复杂,这取决于它提供的服务类型(例如,分组网络的可靠交付可能会丢弃数据)。会话表示运行中的应用(例如, cookies 用于 Web 浏览器的 Web 登录会话过程中)之间的交互,会话层协议可提供例如连接初始化和重新启动、增加检查点(保存到目前为止已完成的工作)等功能。在会话层之上是表示层,它负责信息的格式转换和标准化编码。正如我们所看到的, Internet 协议不包括正式的会话层或表示层,如果需要的话,这些功能由应用程序来实现。
最高层是应用层。各种应用通常会实现自已的应用层协议,它们对用户来说是最容易看到的。目前已存在大量的应用层协议,并且程序员仍在不断开发新协议。因此,应用层是创新最多,以及新功能开发和部署的地方。
1.2.2 分层实现中的复用、分解和封装
分层体系结构的一个主要优点是具有协议复用的能力。这种复用形式允许多种协议共存于同一基础设施中。它也允许相同协议对象(例如连接)的多个实例同时存在,并且不会被混淆。
复用可以发生在不同层,并在每层都有不同类型的标识符,用于确定信息属于哪个协议或信息流。例如,在链路层,大多数的链路技术(例如以太网和 Wi-Fi )在每个分组中包含一个协议标识符字段,用于指出链路层帧携带的协议(IP 是这种协议)。当某层的一个称为协议数据单元(PDU)的对象(分组、消息等)被低层携带时,这个过程称为在相邻低层的封装(作为不透明数据)。因此,第 N 层的多个对象可以通过第 N-1 层的封装而复用。图 1-3 显示了封装的工作过程。第 N-1 层的标识符在第 N 层的分解过程中用于决定正确的接收协议或程序。
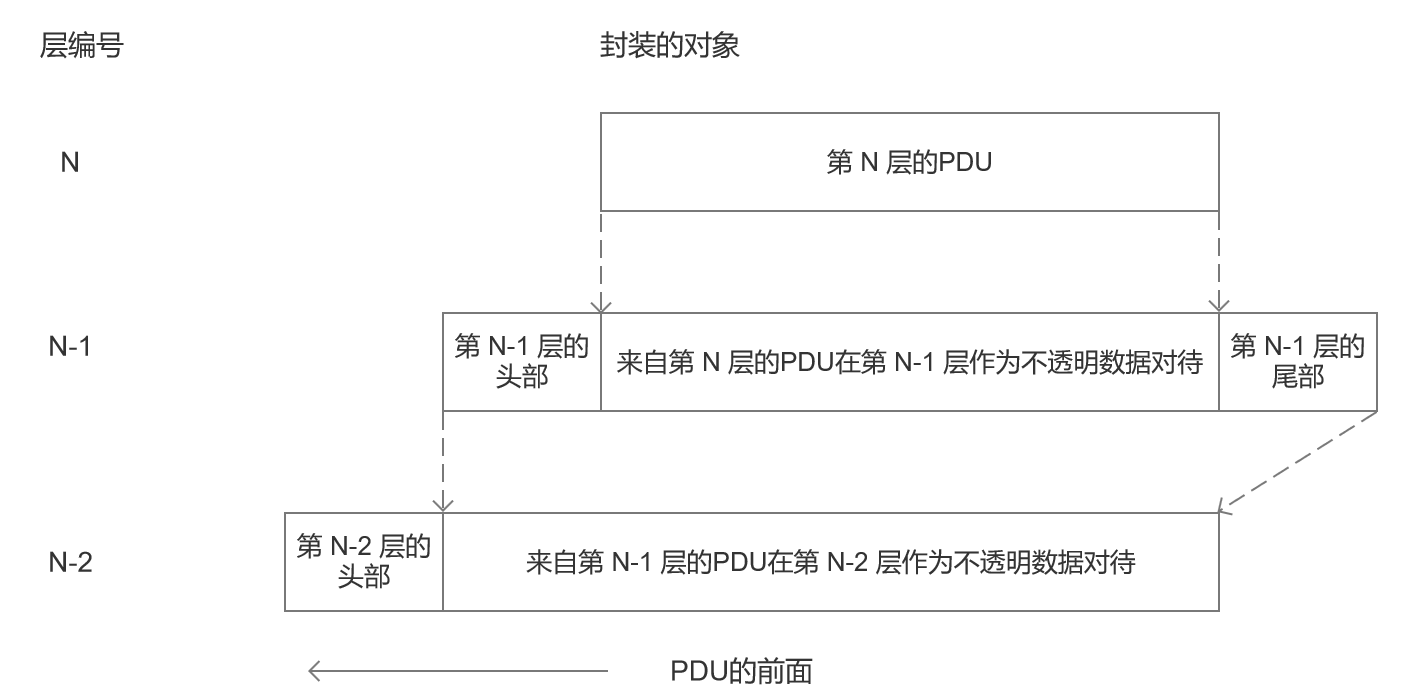
图 1-3 封装通常与分层一起使用。单纯的封装涉及获得某层的 PDU,并在低层将它作为不透明(无须解释)的数据来处理。封装发生在发送方,拆封(还原操作)发生在接收方。多数协议在封装过程中使用头部,少数协议也使用尾部
在图1-3中,每层都有自已的消息对象(PDU)的概念,对应于负责创建它的那个特定层。例如,如果第4层(传输层)协议生成一个分组,将它称为第4层 PDU 或传输层 PDU(TPDU)更准确。如果某层获得由它的上层提供的 PDU,它通常“承诺”不查看 PDU 中的具体内容。这是封装的本质,每层都将来自上层的数据看成不透明、无须解释的信息。最常见的处理是某层在获得的 PDU 前面增加自已的头部,有些协议是增加尾部(不是 TCP/IP)。头部用于在发送时复用数据,接收方基于一个分解(拆分)标识符执行分解。在 TCP/IP 网络中,这类标识符通常是硬件地址、 IP 地址和端口号。头部中也包含一些重要的状态信息,例如一条虚电路是正在建立还是已经建立。由此产生的对象是另一个 PDU。
图1-2 建议的分层的另一个重要特点是:在单纯的分层中,并不是所有网络设备都需要实现所有层。图 1-4 显示在某些情况下,如果设备只希望执行特定操作,那么它只需要实现少数几层。
在图 1-4 中,有些理想化的小型互联网络包括两种端系统,即交换机和路由器。在本图中,每个编号对应于在特定层中的一种协议。正如我们所见,每个设备实现协议栈的一个子集。左侧的主机对应的物理层实现了 3 种链路层协议(D、 E 和 F),以及运行在同一网络层协议上的3种传输层协议(A、 B 和 C)。端主机实现了所有层,交换机实现到第 2 层(这台交换机实现了 D 和 G),路由器实现到第 3 层。由于路由器具有互联不同类型的链路层网络的能力,因此它必须为互联的每种网络实现链路层协议。
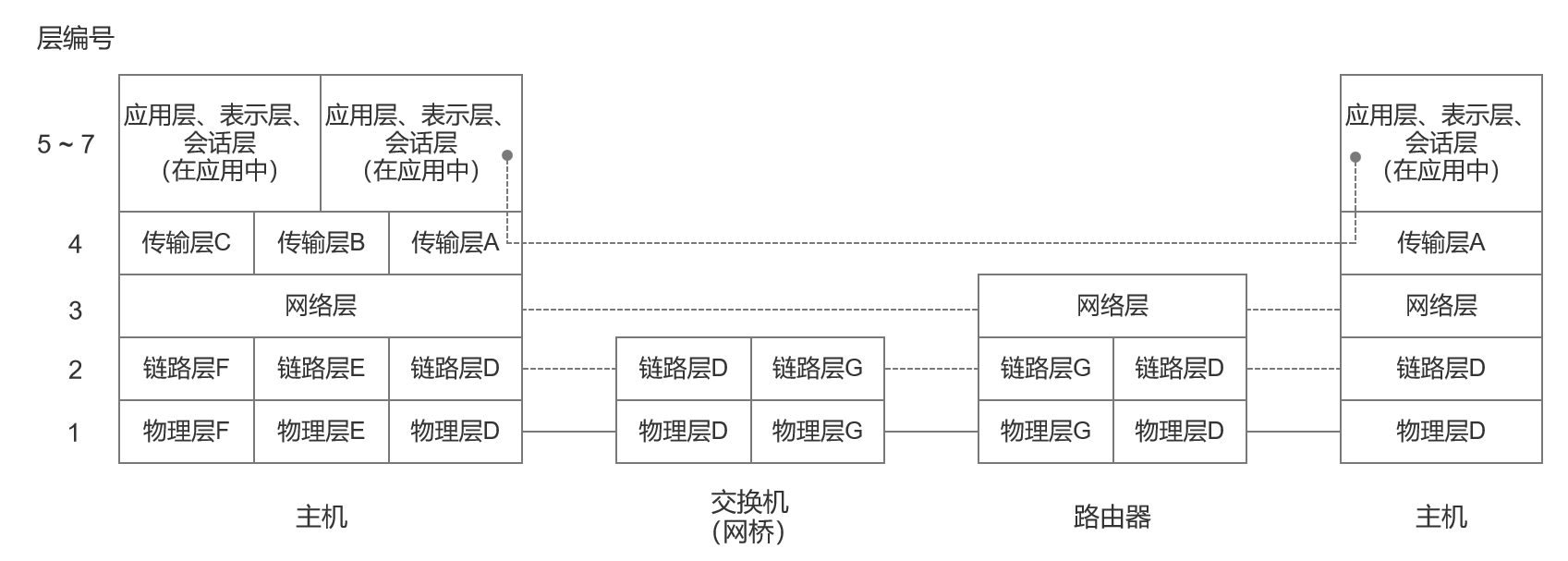
图 1-4 不同的网络设备实现协议栈的不同子集。端主机通常实现所有层。路由器实现传输层之下的各层。这种理想化的结构经常被破坏,这是由于路由器和交换机通常包括类似于主机的功能(例如管理和建立),因此它们需要实现所有层,即使有些层很少使用
尽管我们只显示两台主机之间的通信,但是链路层和物理层网络(标记为 D 和 G)可能连接多台主机。如果这样,可以在任意两台实现相应的高层协议的系统之间通信。在图 1-4 中,针对一个特定的协议族,可以区分为端系统(两边的两台主机)和中间系统(中间的路由器)。网络层之上的各层使用端到端协议。在我们的描述中,只有端系统需要这些层次。但是,网络层提供了一种逐跳协议,它用于两个端系统和每个中间系统。通常不认为交换机或桥接是一个中间系统,这是由于它们没有使用互联网络协议的地址格式来编址,并在很大程度上以透明于网络层协议的方式运行。从路由器和端系统的角度来看,交换机或网桥实际是不可见的。
顾名思义,路由器有两个或更多的网络接口(由于它连接两个或多个网络)。有多个接口的系统称为多宿主。一台主机也可以是多宿主的,但除非它专门将分组从一个接口转发到另一个接口,否则不能把它称为路由器。另外,路由器不一定只是在网络中转发分组的特殊硬件设备。在多数的 TCP/IP 实现中,如果正确配置的话,允许多宿主主机作为路由器使用。在这种情况下,我们可以把该系统称为主机(当它运行文件传输协议(FTP) [RFCO959] 或 Web 应用时)或路由器(当它将分组从一个网络转发到另一个网络时)。我们将结合上下文使用相关的术语。
互联网络的目标之一是对应用隐藏所有关于物理布局(拓扑)和低层协议的异构性的细节。虽然在图 1-4 所示的由两个网络组成的互联网络中并不明显,但应用层不关心(不在乎)以下事实:尽管连接在网络中的主机都采用链路层协议 D (例如以太网),但主机之间由采用链路层协议 G 的路由器和交换机隔开。主机之间可能有 20 个路由器,它们可采用其他类型的物理连接,应用程序无须修改即可运行(虽然性能可能有所不同)。以这种方式对细节加以抽象是促使互联网络概念变得强大和有用的原因。
1.3 TCP/IP 协议族结构
到目前为止,我们已讨论了体系结构、协议、协议族和抽象的实现技术。在本节中,我们将讨论构成 TCP/IP 协议族的体系结构和特定协议。虽然这已成为 Internet 使用的协议的既定术语,但是也有很多 TCP 和 IP 之外的协议被包含在 Internet 使用的协议集或协议族中。我们将从最终形成 Internet 协议分层基础的ARPANET参考模型开始,研究它与前面讨论的 OSI 参考模型的区别。
1.3.1 ARPANET 参考模型
图 1-5 描述了源于 ARPANET 参考模型的分层,它最终被 TCP/IP 协议族采纳。它的结构比 OSI 模型更简单,但在实现中包括一些特定协议,并且不适合于常规层次的简化。

图 1-5 基于 ARM 或 TCP/IP 的协议分层被用于 Internet。这里没有正式的会话或表示层。另外,这里有几个不适合归入标准层的“附属”或辅助协议,它们为其他协议的运行提供重要功能。其中有些协议没有被 IPv6 使用(例如 IGMP 和 ARP)。
从图 1-5 底部沿着协议栈上移,我们首先看到的层次是 2.5,这是一个“非正式”的层。有几个协议工作在这层,一个最古老和最重要的协议是地址解析协议(ARP)。它是 IPv4 的专用协议,只用于多接入链路层协议(例如以太网和 Wi-Fi),完成IP层使用的地址和链路层使用的地址之间的转换。我们将在第4章讨论这个协议。IPv6的地址映射功能作为 ICMPv6 的一部分,我们将在第 8 章讨论。
我们在图 1-5 中编号为 3 的层中看到 IP,它是 TCP/IP 中最重要的网络层协议。我们将在第 5 章讨论它的细节。 IP 发送给链路层协议的 PDU 称为 IP 数据报,它的大小是 64KB(IPv6 将它扩大为 4GB)。在很多情况下,当使用的上下文是清晰的,我们将会使用简化的术语“分组”来表示 IP 数据报。大的分组放入链路层 PDU (称为帧)时需要进行缩小处理,这个过程称为分片,它通常由 IP 主机和某些路由器在必要时执行。在分片的过程中,大数据报的一部分被放入多个称为分片的小数据报中,并在到达目的地后组合(称为重组)。我们将在第 10 章中讨论分片。
在本书中,我们使用术语 IP 表示 IP 版本 4 和 6 ,使用 IPv6 表示 IP 版本 6,并使用 IPv4 表示 IP 版本 4,它是当前最流行的版本。在讨论体系结构时,我们很少关注 IPv4 和 IPv6 的细节。当我们讨论寻址和配置的工作原理(第 2 章和第 6 章)时,这些细节将变得更重要。
由于每个 IP 分组都是一个数据报,所以都包含发送方和接收方的第 3 层地址。这些地址称为 IP 地址,即 32 位的 IPv4 地址或 128 位的 IPv6 地址;我们将在第 2 章详细讨论它们。IP 地址长度不同是 IPv4 和 IPv6 之间的最大差别。每个数据报的目的地址用于决定将该数据报发送到哪里,而做出此决定和发送数据报到下一跳的过程称为转发。路由器和主机都能进行转发,但更多的是由路由器实现转发。这里有 3 种类型的IP地址,地址类型决定如何进行转发:单播(目的地是一台主机)、广播(目的地是一个指定网络中的所有主机)和组播(目的地是属于一个组播组中的一组主机)。第 2 章将详细介绍与 IP 一起使用的地址类型。
Internet控制消息协议(ICMP)是IP的一个辅助协议,我们将它标注为 3.5 层协议。 IP 层使用它与其他主机或路由器的IP层之间交换差错消息和其他重要信息。 ICMP有两个版本:IPv4 使用的ICMPv4, IPv6使用的 ICMPv6。 ICMPv6 是相当复杂的,包括地址自动配置和邻居发现等功能,它们在IPv4网络中由其他协议(例如ARP)处理。虽然 ICMP 主要由 IP 使用,但它也能被其他应用使用。事实上,两个流行的诊断工具( ping 和 traceroute )都使用 ICMP。 ICMP 消息被封装在 IP 数据报中,采用与传输层 PDU 相同的封装方式。
Internet组管理协议( IGMP)是 IPv4 的另一个辅助协议。它采用组播寻址和交付来管理作为组播组成员的主机(一组接收方接收一个特定目的地址的组播流量)。我们在这里只描述广播和组播的一般特点,在第 9 章介绍 IGMP 和组播监听发现(MLD,用于IPv6)协议。
在第 4 层中,常见的两种 Internet 传输协议有很大区别。广泛使用的传输控制协议(TCP)会处理数据包丢失、重复和重新排序等 IP 层不处理的问题。它采用面向连接(VC)的方式,并且不保留消息边界。相反,用户数据报协议(UDP)仅提供比 IP 协议稍多的功能。 UDP允许应用发送数据报并保留消息边界,但不强制实现速率控制或差错控制。
TCP 在两台主机之间提供可靠的数据流传输。 TCP 涉及很多工作,例如将来自应用的数据分解成在网络层中传输的适当尺寸的块,确认接收到的分组和设置超时,以便对方能够确认自已发送的分组。由于传输层提供这种可靠的数据流,所以应用层可以忽略这些细节。TCP 发送到 IP 的 PDU 称为** TCP 段**。
另一方面, UDP 为应用层提供一种更简单的服务。它允许将数据报从一台主机发送到另一台主机,但不保证数据报能到达另一端。任何可靠性都需要由应用层提供。事实上, UDP 所做的是提供一套端口号,用于复用、分解数据和校验数据的完整性。正如我们所看到的,即使 UDP 和 TCP 在同一层次,它们也是完全不同的。这里给出每种传输层协议的用途,我们可看到使用 TCP 和 UDP 的不同应用。
这里还有两个传输层协议,它们相对比较新,并被用于某些系统中。由于它们的使用还不是很广泛,所以我们没对它们进行太多讨论,但它们是值得注意的。首先是数据报拥塞控制协议(DCCP),它在 [RFC4340] 中定义。它提供了一种介于 TCP 和 UDP 之间的服务类型:面向连接、不可靠的数据报交换,但具有拥塞控制功能。拥塞控制包括发送方控制发送速率的多种技术,以避免流量堵塞整个网络。我们将在第 16 章中结合 TCP 详细介绍拥塞控制。
另一个是流控制传输协议(SCTP),它在 [RFC4960] 中定义,是用于某些特定系统的传输协议。 SCTP 提供类似于 TCP 的可靠交付,但不要求严格保持数据的顺序。它还允许多个数据流逻辑上在同一连接上传输,并提供了一个消息抽象,这是它与 TCP 的主要区别。SCTP 用于在 IP 网络上携带信令消息,这类似于某些电话网络中的用途。
在传输层之上,应用层负责处理特定应用的细节。有很多常见的应用,几乎每个应用的实现都是基于 TCP/IP 的。应用层与应用的细节有关,但与网络中的数据传输无关。较低的三层则相反:它们对具体应用一无所知,但需要处理所有的通信细节。
1.3.2 TCP/IP 中的复用、分解和封装
我们已讨论了协议复用、分解和封装的基础内容。每层都会有一个标识符,允许接收方决定哪些协议或数据流可复用在一起。每层通常也有地址信息,它用于保证一个 PDU 被交付到正确的地方。图 1-6 模拟了如何在一台 Internet 主机上进行分解。
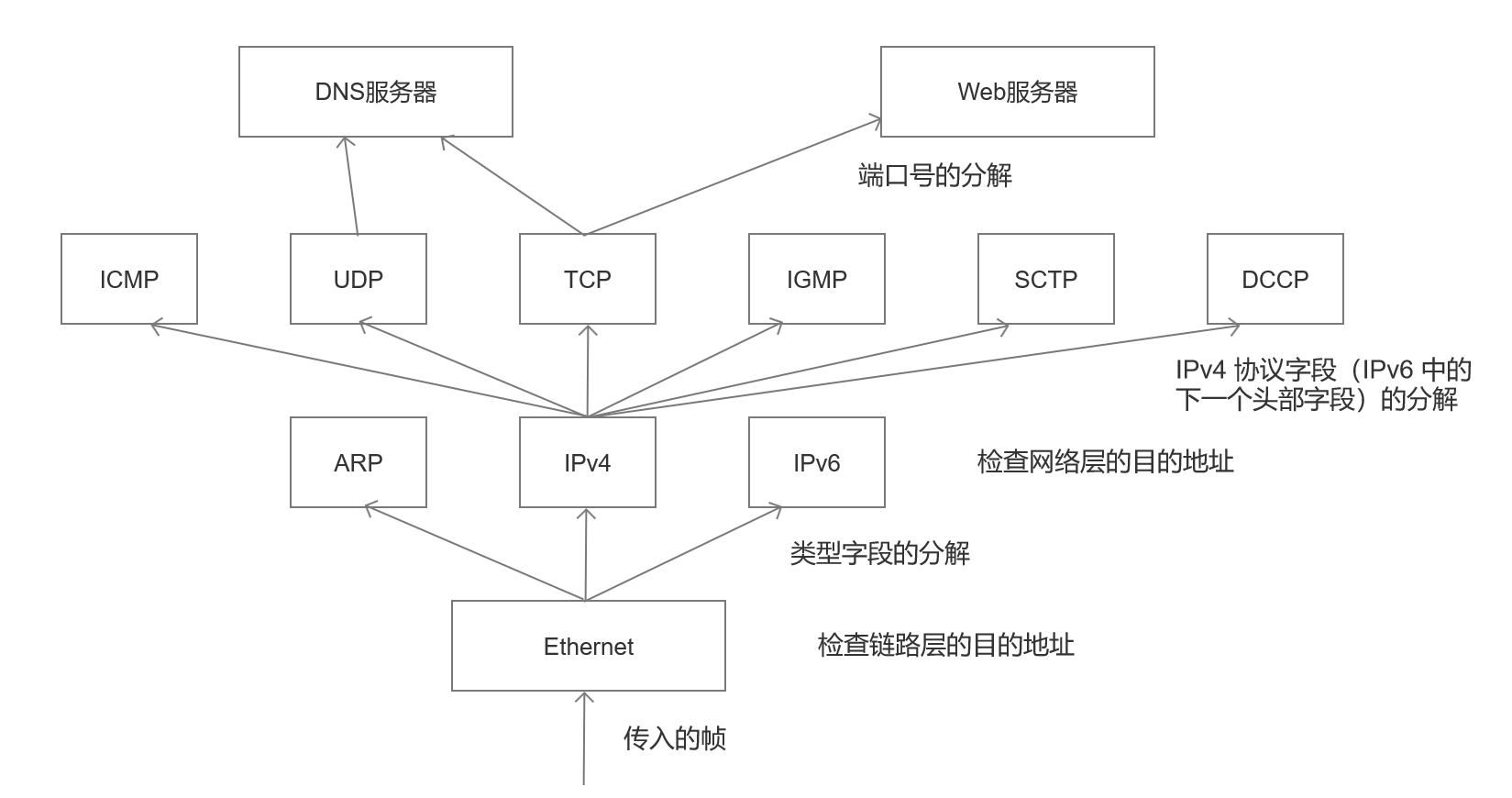
图 1-6 TCP/IP 协议栈将地址信息和协议分解标识符相结合,以决定一个数据报是否被正确接收,以及哪个实体将会处理该数据报。有几层还会检测数值(例如校验和),以保证内容在传输中没有损坏
虽然它不是 TCP/IP 协议族的真实部分,但我们也能自底向上地说明从链路层开始如何进行分解,这里使用以太网作为例子。我们在第 3 章讨论几种链路层协议。以太网帧包含一个 48 位的目的地址(又称为链路层或介质访问控制(MAC)地址)和一个16位的以太网类型字段。 0x0800 (十六进制)表示这个帧包含 IPv4 数据报。 0x0806 和 0x86DD 分别表示 ARP 和 IPv6。 假设目的地址与接收方的一个地址匹配,这个帧将被接收并校验差错,以太网类型字段用于选择处理它的网络层协议。
如果接收到的帧包含一个IP数据报,以太网头部和尾部信息将被清除,并将剩余字节(包含帧的有效载荷)交给 IP 来处理。 IP检测一系列的字段,包括数据报中的目的 IP 地址。如果目的地址与自已的一个IP地址匹配,并且数据报头部(IP不检测有效载荷)没有错误,则检测 8 位的 IPv4 协议字段(在 IPv6 中称为下一个头部字段),以决定接下来调用哪个协议来处理。常见的值包括1 (ICMP)、 2 (IGMP)、 4 (IPv4)、 6 (TCP) 和 17 (UDP)。数值4 (和41,表示 IPv6 )的含义是有趣的,因为它表示一个 IP 数据报可能出现在另一个 IP 数据报的有效载荷中。它违反了分层和封装的原有概念,但是作为隧道技术的基础,我们在第3章进行更多讨论。
如果网络层( IPv4 或 IPv6 )认为传入的数据报有效,并且已确定正确的传输层协议,则将数据报(必要时由分片重组而成)交给传输层处理。在传输层中,大部分协议(包括 TCP 和 UDP )通过端口号将复用分解到适当的应用。
1.3.3 端口号
端口号是 16 位的非负整数(范围是0 - 65535)。这些数字是抽象的,在物理上没有指任何东西。相反,每个IP地址有 65536 个可用的端口号,每个传输协议可使用这些端口号(在大多数情况下),它们被用于确定正确的接收数据的具体服务。对于客户机/服务器应用(见 1.5.1 节),一台服务器首先“绑定”到一个端口号,然后一个或多个客户机可使用某种特定的传输协议与一台服务器上的端口号建立连接。从这个意义上来说,端口号的功能更像电话号码的扩展,差别是它们通常是由某个标准来分配。
标准的端口号由 Internet 号码分配机构(IANA)分配。这组数字被划分为特定范围,包括熟知端口号(0 ~ 1023)、注册端口号( 1024 ~ 49151 )和动态/私有端口号(49152 ~ 65535)。在传统上,服务器需要绑定到(即在上面提供服务)一个熟知端口,它需要管理员或“根”访问这样的特殊权限。
熟知端口用于识别很多众所周知的服务,例如安全外壳协议(SSH,端口22)、 FTP (端口 20 和 21)、 Telnet远程终端协议(端口 23)、电子邮件/简单邮件传输协议(SMTP,端口 25)、域名系统(DNS,端口 53)、超文本传输协议或Web(HTTP和HTTPS,端口 80 和 443)、交互式邮件访问协议( IMAP 和IMAPS,端口 143 和 993 )、简单网络管理协议(SNMP,端口 161 和 162 )、轻量级目录访问协议(LDAP,端口 389 ),以及其他几种服务。拥有多个端口的协议(例如 HTTP 和 HTTPS )通常使用不同端口号,这取决于是否将传输层安全(TLS)与基础的应用层协议共同使用(见第 18 章)。
注意 如果我们测试这些标准服务和其他 TCP/IP 服务(Telnet、 FTP、 SMTP等)使用的端口
号,会发现它们大多数是奇数。这是有历史原因的,这些端口号从NCP端口号派生而来( NCP是网络控
制协议,在 TCP 之前作为 ARPANET 的传输层协议)。NCP 虽然简单,但不是全双工的,因此每个
应用需要两个连接,并为每个应用保留奇偶成对的端口号。当 TCP 和 UDP 成为标准的传输层协议
时,每个应用只需要一个端口号,因此来自 NCP 的奇数端口号被使用。
注册端口号提供给有特殊权限的客户机或服务器,但 IANA 会维护一个为特定用途而保留的注册表,开发新应用时通常应避免使用这些端口号,除非你已购买某些 IANA 分配的端口号。动态/私有端口号基本不受监管。正如我们所看到的,在某些情况下(例如在客户端),端口号的值无关紧要,这是因为它们只是短期被使用。这些端口号又称为临时端口号。它们被认为是临时的,因为客户机只需支持一个应用的客户程序,并不需要被服务器发现以建立一个连接。相反,服务器通常需要不变的名称和端口号,以便被客户机所发现。
1.3.4 名称、地址和 DNS
在 TCP/IP 中,每台计算机(包括路由器)的每个链路层接口至少有一个IP地址。 IP 地址足以识别主机,但它们不方便被人们记忆或操作(尤其是更长的 IPv6 地址)。在 TCP/IP 环境中, DNS 是一个分布式数据库,提供主机名和 IP 地址之间的映射(反之亦然)。域名建立是有层次的,以 .com、.org、.gov、.in、.uk 和 .edu 等域结尾。 DNS 是一个应用层协议,因此它的运行依赖于其他协议。虽然大多数 TCP/IP 协议不必关心域名,但用户(例如使用 Web 浏览器)通常会频繁使用域名,因此如果 DNS 不能正常工作,正常的 Internet 访问也难以使用。第 11 章将详细介绍 DNS。
执行域名操作的应用可以调用一个标准的 API 函数(见 1.5.3 节),将需要查找的 IP 地址(或地址)对应到一个主机名。同样,另一个函数提供反向查找功能,为一个给定的 IP 地址查找对应的主机名。大多数应用程序将主机名作为输人,但是经常也需要一个IP地址。 Web 浏览器支持这种功能。例如,在浏览器中输人统一资源定位符(URL), http://131.243.2.201/index.html 和 http://[2001:400:610:102::C9]/index.html,它们等效于 http://ee.lbl.gov/index.html (在写作时,第二个例子需要成功建立 IPv6 连接)。
1.4 Internet、内联网和外联网
如前所述, Internet (因特网)已发展成为由很多网络互联起来的网络集合。小写字母开头的 internet 表示使用常见协议族互联的多个网络。大写字母开头的 Internet 表示可使用 TCP/IP 通信的世界范围的主机集合。 Internet 是一个 internet,但反过来说是错误的。
组网在 20 世纪 80 年代得到快速发展的原因之一,那就是很多相互隔离的单机系统组合起来后作用并不明显。几个独立的系统连接起来组成一个网络。虽然已向前迈进了一步,但我们在 20 世纪 90 年代意识到,不能互操作的独立网络不如一个更大的网络有价值。这个概念是 Metcalfe 定律的基础,计算机网络价值大致与连接的端系统(例如用户或设备)数量的平方成正比。 Internet 构想和它支持的协议使不同网络互联成为可能。实际上,这个看似简单的概念非常有用。
最容易的方式是构造一个由路由器连接两个或多个网络的互联网络。路由器通常是连接网络的一台专用设备,其优点是提供很多不同物理网络的连接,例如以太网、 Wi-Fi、点到点链路、 DSL、电缆 Internet 服务等。
注意 这些设备又被称为 IP 路由器,但我们将使用路由器这个术语。这些设备在历史上曾被称为网
关,这个术语用于很多比较旧的 TCP/IP 文献中。当前的网关术语用于表示应用层网关 (ALG),它
为一个特定应用(通常是电子邮件或文件传输)连接两个不同协议族( TCP/IP 和 IBM 的 SNA)。
近年来,一些其他术语已被采用 TCP/IP 协议的各种互联网络所采纳。内联网是一个用于描述专用互联网络的术语,它通常由一个商业机构或其他企业来运行。大多数情况下,内联网提供的访问资源只供特定企业的成员使用。用户可使用虚拟专用网(VPN)连接到(例如企业)内联网。 VPN 有助于保证内联网中潜在的敏感资源只供授权用户访问,它通常使用前面提到的隧道概念。我们将在第7章详细讨论 VPN。
在很多情况下,一个企业或商业机构可能希望建立一个网络,其中包含可供合作伙伴或其他相关公司通过 Internet 访问的服务器。这种涉及 VPN 的网络通常被称为外联网,由连接在提供服务的企业防火墙之外的计算机组成(见第 7 章)。从技术上来说,内联网、外联网和 Internet 之间的差别不大,但使用方式和管理策略通常不同,并由此出现更多的专业术语。
1.5 设计应用
到目前为止,我们已接触的网络概念提供了一个简单的服务模型 [RFC6250] :在运行于不同(或相同)计算机上的程序之间传输数据。通过这种能力可完成任何有用的事。我们需要使用网络应用来提供服务或执行计算。网络应用的典型结构基于少数几种模式。最常见的模式是客户机/服务器模式和对等模式。
1.5.1 客户机 / 服务器
大多数网络应用被设计为一端是客户机,而另一端是服务器。服务器为客户机提供某类服务,例如访问服务器主机中的文件。我们可以将服务器分为两类:迭代和并发。迭代服务器经过以下步骤:
- 等待客户机请求到达。
- 处理客户机请求。
- 将响应发送给请求的客户机。
- 回到步骤 1。
迭代服务器的问题是步骤 2 需要经过较长时间。在此期间,无法为其他客户机服务。并发服务器经过以下步骤:
- 等待客户机请求到达。
- 启用一个新服务器实例来处理客户机请求。这可能实际创建一个新的进程、任务或线程,它依赖于底层操作系统的支持。这个新的服务器处理一个客户机的全部请求。当请求的任务完成后,这个新的服务器终止。同时,原有服务器实例继续执行 3。
- 回到步骤 1。
并发服务器的优点是服务器只产生其他服务器实例,并由它们来处理客户机请求。本质上,每个客户都有自已的服务器。假设操作系统支持多个程序(目前所有操作系统基本都支持),则多个客户机可以同时得到服务。我们将原因归于服务器而不是客户机,这是由于客户机通常无法判断与它通信的是迭代或并发服务器。大多数服务器通常是并发的。
注意,我们使用术语客户机和服务器表示应用,而不是应用所运行的特定计算机系统。相似的术语有时用于表示执行客户机或服务器应用的硬件。虽然这些术语有时并不准确,但它们在实际应用中表现良好。因此,我们通常发现一个服务器(硬件)上运行着多个服务器(应用)。
1.5.2 对等
有些应用以更分布式的形式设计,其中没有专门的服务器。相反,每个应用既是客户机,又是服务器,有时同时是两者,并能转发请求。有些很流行的应用(例如 Skype [SKYPE] 、 BitTorrent[BT] )采用这种式。这种应用称为对等或 P2P 应用。并发的 P2P 应用接收到传入的请求,确定它是否能响应这个请求,如果不能,将这个请求转发给其他对等方。因此,一组 P2P 应用共同形成一个应用网络,也称为覆盖网络。目前,这种覆盖网络是常见的,并且功能强大。例如, Skype 已发展成国际电话呼叫的最大运营商。根据某些估计,在 2009 年, BitTorrent 已占所有 Internet 流量的一半以上 [IPIS ]。
P2P网络的一个主要问题是发现服务。也就是说,一个对等方如何在一个网络中发现提供它所需的数据或服务的其他对等方,以及可能进行交互的那些对等方的位置?这通常由一个引导程序来处理,以便每个客户机在最初配置中使用它所需的对等方的地址和端口号。一旦连接成功,新的参与者向其他活跃的对等方发出请求,并根据协议获得对等方提供的服务或文件。
1.5.3 应用程序编程接口
无论是 P2P 或客户机/服务器,都需要表述其所需的网络操作(例如建立一个连接、写入或读取数据)。这通常由主机操作系统使用一个网络应用程序编程接口(API)来实现。最流行的 API 被称为套接字 Berkeley 套接字,它最初由 [LJFK93] 开发。
本书不是讲述网络编程的,我们只是通过介绍它说明 TCP/IP 的特点,以及哪个特点是由套接字 API 提供的。针对套接字的编程例子细节见 [SFR04] 。对于IPv6的套接字修改的描述,大量在线文档 [RFC3493] 、 [RFC3542] 、 [RFC3678] 、 [RFC4584] 、 [RFC5014] 免费提供。
1.6 标准化进程
刚接触TCP/IP协议族的新手通常不了解谁负责各种协议的制定和标准化,以及它们如何运作。有些组织负责解决这个问题。我们最常关注的组织是 Internet 工程任务组(IETF)[RFC4677] 。这个组织每年在世界不同地点举行3次会议,以便开发、讨论和通过 Internet 的“核心”协议标准。究竟什么构成“核心”是有争论的,但常见协议(例如IPv4、 IPv6、TCP、 UDP 和 DNS)显然属于此列。 IETF 会议对所有人开放,但它不是免费的。
IETF是一个论坛,它选举出称为 Internet 架构委员会(IAB)和 Internet 工程指导组(IESG)的领导组织。 IAB 负责提供 IETF 活动指导和执行其他任务,例如任命其他标准制定组织(SDO)的联络员。IESG 具有决策权力,可以修改现有标准,以及建立和审批新的标准。”繁重“或细致的工作通常由 IETF 工作组执行,工作组主席负责协调执行此任务的志愿者。
除了 IETF,还有另外两个重要组织与 IETF 密切合作。 Internet 研究任务组(IRTF)讨论那些没有成熟到足以形成标准的协议、体系结构和程序。 IRTF 主席是 IAB 的列席成员。 IAB 和 Internet 协会(ISOC)共同影响和促进世界范围的有关 Internet 投术和使用的政策和培训。
1.6.1 RFC
Internet 社会中的每个官方标准都以一个 RFC (征求意见)的形式发布。 RFC可以通过多种方式创建, RFC 发布者(RFC编者)对一个已发布的 RFC 创建多个文件。当前文件(在 2010 年)包括 IETF、IAB、IRTF 和独立提交的文件。在被接受并作为 RFC 发布之前,文件将作为临时的 Internet 草案存在,在编辑和审查过程中将接收意见和公布进展。
不是所有 RFC 都是标准。只有标准跟踪类别的 RFC 被认为是官方标准。其他类别包括当前最佳实践(BCP)、信息、实验和历史。重要的是,一个文件成为一个 RFC,并不意味着 IETF 已采纳它作为标准。事实上,针对现有 RFC 有明显分歧。
RFC 的大小不等,从几页到几百页。每个 RFC 由一个数字来标识,例如 RFC 1122,新 RFC 被赋予更大的数字。它们可以从一些站点免费获得,包括 http://www.rfceditor.org 。由于历史原因,下载的 RFC 通常是基本的文本文件,虽然有些 RFC 已使用更先进的文件格式来格式化或撰写。
许多 RFC 具有特殊意义,它们总结、澄清或解释其他一些特殊标准。例如, [RFC5000] 定义了一组其他 RFC (这个 RFC 最近正在撰写中),它们在 2008 年中期被视为官方标准。一个更新列表见当前标准站点 [OIPSW] 。主机需求 RFC ([RFC1122] 和 [RFC1123] )定义 Internet 中 IPv4 主机的协议实现,路由器需求 RFC [RFC1812] 对路由器进行相同定义。节点需求 RFC [RFC4294] 对 IPv6 系统进行上述定义。
1.6.2 其他标准
虽然 IETF 负责我们在书中讨论的大部分协议的标准化,但是其他SDO负责定义的协议同样值得我们注意。这些重要组织包括电气和电子工程师学会(IEEE)、万维网联盟(W3C)以及国际电信联盟(ITU)。在本书描述的相关活动中, IEEE 关注第 3 层以下标准(例如 Wi-Fi 和以太网), W3C关注应用层协议,特别是那些涉及 Web 的技术(例如基于 HTML 的语法)。 ITU特别是 ITU-T (原来的 CCITT)标准化的协议用于电话和蜂窝网络,它正成为 Internet 中一个越来越重要的组成部分。
1.7 实现和软件分发
实际上,标准的 TCP/IP 实现来自加州大学伯克利分校计算机系统研究组(CSRG)。它们通过 4.x BSD 系统发布,直到 20 世纪 90 年代中期才出现 BSD 网络发布版。这个源代码已成为许多其他实现的基础。今天,每个流行的操作系统都有自已的实现。在本书中,我们倾向于以 Linux、 Windows 的 TCP/IP 实现为例,有时也采用 FreeBSD 和 Mac OS (两者都由 BSD 版本派生而来)。在大多数情况下,某些特定实现通常无关紧要。
图 1-7 显示了各种 BSD 版本的年代列表,给出了我们在后面章节中涉及 TCP/IP 的重要特点。它也显示了 Linux 和 Windows 开始支持 TCP/IP 的时间。 BSD 网络发布版显示在第二列,它是免费提供的公共源代码发布版,其中包括所有网络代码,既包括协议本身,又包括很多应用程序和实用工具(例如 Telnet 远程终端程序和 FTP 文件传输程序)。
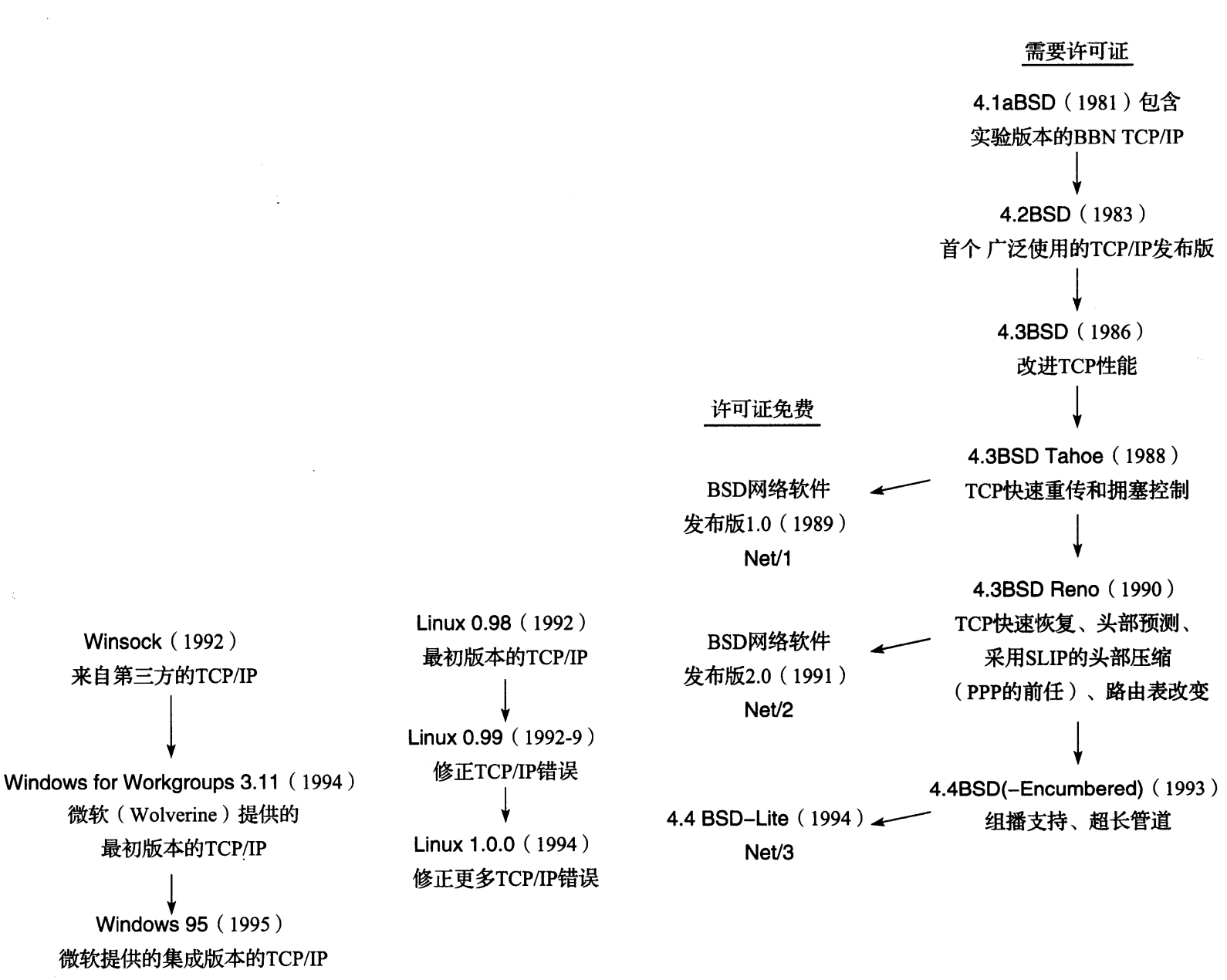
图 1-7 软件版本支持 TCP/IP 的历史可追溯到 1995 年。各种 BSD 版本率先支持 TCP/IP。 在 20 世纪 90 年代早期,由于 BSD 版本的合法性不确定, Linux 最初是为 PC 用户量身定制的代替品。几年后,微软开始在 Windows 中支持 TCP/IP
20 世纪 90 年代中期, Internet 和 TCP/IP 已很好地被实现。随后,所有流行的操作系统都开始支持 TCP/IP 协议。通过研究 TCP/IP 的新特点发现,之前首先出现在 BSD 版本中的功能,现在通常首先出现在 Linux 版本中。最近, Windows 已实现了一个新的 TCP/IP 协议栈(从 Windows Vista 开始),它具备很多新特点和本地 IPv6 功能。Linux、FreeBSD、MacOS X也支持 IPv6,并且不需要设置任何特殊配置选项。
1.8 与 Internet 体系结构相关的攻击
在整本书中,我们将简要描述攻击和漏洞,这些内容在讨论设计或实现主题时已谈到。很少有攻击将 Internet 体系结构整体作为目标。但是,值得注意的是, Internet 体系结构交付 IP 数据报是基于目的 IP 地址。因此,恶意用户能在自已发送的每个 IP 数据报的源地址字段中插人任何 IP 地址,这种行为称为欺骗。生成的数据报被交付到目的地,但难以确定它的真实来源。也就是说,很难或不能确定从 Internet 中接收的数据报来源。
欺骗可以与 Internet 中出现的各种攻击相结合。拒绝服务(DoS)攻击通常涉及消耗大量的重要资源,以导致合法用户被拒绝服务。例如,向一台服务器发送大量 IP 数据报,使它花费所有时间处理接收的分组和执行其他无用的工作,这是一种类型的 DoS 攻击。有些 DoS 攻击可能涉及以很多流量堵塞网络,导致其无法发送其他分组。这通常需要使用很多计算机来发送,并形成一个**分布式DoS (DDoS)**攻击。
未授权访问攻击涉及以未授权方式访问信息或资源。它可以采用多种技术来实现,例如利用协议实现上的错误来控制一个系统(称为占有这个系统,并将它变成一个僵尸)。它也可以涉及各种形式的伪装,例如攻击者的代理冒充一个合法用户(例如运行用户证书)。有些更恶毒的攻击涉及使用恶意软件(malware)控制很多远程系统,并以一种协同、分布式的方式(称为僵尸网络(botnets))使用它们。那些出于(非法)获利或其他恶意目的而有意开发恶意软件和利用系统的程序员通常称为黑帽。所谓的白帽也在利用同样的技术做这方面的事情,但他们只是通知系统存在漏洞而不是利用它们。
关于 Internet 体系结构,值得注意的是,最初的 Internet 协议没有进行任何加密,加密可用于支持认证、完整性或保密。因此,恶意用户仅通过分析网络中的分组,通常就可以获得私人信息。如果具有修改传输中的分组的能力,他就可以冒充用户或更改消息内容。虽然这些问题由于加密协议(见第 18 章)而显著减少,但旧的或设计不当的协议有时在简单的窃听攻击面前仍很脆弱。由于无线网络的流行,“嗅探”其他人发送的分组比较容易,因此应避免使用旧的或不安全的协议。注意,虽然可在某层(例如 Wi-Fi 网络的链路层)启用加密,但只有主机到主机的加密(IP 层或以上)能保护穿过多个网段,以及可能采用遍历方式到达最终目的地的 IP 数据报。
1.9 总结
本章快速浏览了网络体系结构和设计,特别是 TCP/IP 协议族的概念,后面章节将详细讨论它们。 Internet 体系结构被设计成支持现有不同网络互联,同时提供了广泛的服务和协议操作。选择使用数据报的分组交换是看中它的鲁棒性和效率。数据安全性和交付可预测性(例如有限的延迟)是次要原因。
基于对操作系统分层和模块化软件设计的理解,早期的 Internet 协议实现者采纳了经过封装的分层设计。 TCP/IP 协议族的 3 个主要层次是网络层、传输层和应用层,我们前面提到过每层具有不同功能。我们还提到了链路层,它与 TCP/IP 协议关系密切。我们将在以后的章节中详细讨论。
在 TCP/IP 中,网络层和传输层之间的区别至关重要:网络层( IP )提供了一个不可靠的数据报服务,必须由 Internet 中所有可寻址的系统来实现,而传输层( TCP 和 UDP )为端主机上运行的应用程序提供了端到端服务。主要的传输层协议有根本性的差异。 TCP提供了带流量控制和拥塞控制的有序、可靠的流交付。除了用于多路分解的端口号和错误检测机制之外, UDP提供的功能基本没有超越IP。但是,与 TCP 不同, UDP支持组播交付。
每层都使用地址和分解标识符,用以避免混淆不同协议或相同协议的不同关联/连接。链路层多接入网络通常使用 48 位地址;IPv4 使用 32 位地址, IPv6使用 128 位地址。TCP 和 UDP 传输协议使用一系列不同的端口号。有些端口号由标准来分配,有些端口号是临时使用的,通常由客户端与服务器通信时使用。端口号并不代表任何实际内容,它们只是作为应用程序与对方通信的一种方式。
虽然端口号和 IP 地址通常足以识别 Internet 中的一个服务,但它们不方便人们记忆或使用(特别是 IPv6 地址)。因此, Internet 使用了一种层次结构的主机名,可以通过 DNS 将主机名转换为 IP 地址(或者反过来),而DNS是一个运行在 Internet 上的分布式数据库应用程序。 DNS 已成为 Internet 基础设施中的重要组成部分,我们应尽力使它以更安全的方式运行(见第18章)。
互联网络( internet)是一个网络集合,其中最常见的基本设备是路由器,它被用于在 IP 层连接多个网络。 Internet 是一个遍布全球和互联近两亿用户的互联网络(在 2010 年)。专用的互联网络称为内联网,通常使用特殊设备(防火墙,在第 10 章讨论)连接 Internet,它可以防止未授权的访问企图。外联网通常由一个机构的多个内联网组成,它能以有限的方式被合作伙伴或分支机构所访问。
网络应用通常采用客户机/服务器或对等模式设计。客户机/服务器是更流行、更传统的模式,但对等模式也获得了巨大成功。无论哪种设计模式,应用程序都要调用 API 执行网络任务。最常见的 TCP/IP 网络 API 称为套接字。它由 BSD UNIX 发布版提供,其软件版本率先使用 TCP/IP。 20 世纪 90年代末, TCP/IP 协议族和套接字 API 被用于所有流行的操作系统。
安全性不是 Internet 体系结构的主要设计目标。由于端主机易于篡改不安全的 IP 数据报的源 IP 地址,接收方难以确定分组的来源。分布式 DoS 攻击仍是一个挑战,作为受害者的端主机形成僵尸网络进行 DDoS 和其他攻击,而主机所有者通常对这些并不知情。最后,早期的 Internet 协议难以保护敏感信息的隐私,但这些协议中的大多数当前已过时,其现代版本通常采用加密方式为主机之间通信提供保密和认证。
1.10 参考文献
[B64] P.Baran, "On Distributed Communications: 1. Introduction to Distributed Communications Networks," RAND Memorandum RM-3420-PR, Aug. 1964.
[BT] http://www.bittorrent.com
[C88] D.Clark, "The Design Philosophy of the DARPA Internet Protocols," Proc. ACM SIGCOMM, Aug. 1988.
[CK74] V Cerf and R.Kahn, "A Protocol for Packet Network Intercommunication," IEEE Transactions on Communications, COM-22(5), May 1974.
[D08] J.Day Patterns in Network Architecture: A Return to Fundamentals(Prentice Hall, 2008).
[D68] E.Dijkstra, "The Structure of the 'THE'-Multiprogramming system,” Communications of the ACM, 11(5), May 1968.
[DBSW66] D.Davies, K.Bartlett, R.Scantlebury and P Wilkinson, ‘A Digital Communications Network for Computers Giving Rapid Response at Remote Terminals,” Proc. ACM Symposium on Operating System Principles, Oct. 1967.
[I96] IBM Corporation, Systems Network Architecture--APPN Architecture Reference, Document SC30-3422-04, 1996.
[IPIS] Ipoque, Internet Study 2008/2009, http://www.ipoque.com/resources/internet-studies/internet-study-2008_2009
[K64] L.Kleiurock, Communication Nets: Stochastic Message Flow and Delay (McGraw-Hill, 1964).
[LC04] S.Lin and D. Costello Jr., Error Control Coding, Second Edition (Prentice Hall, 2004).
[LJFK93] S.Leffler, W.Joy, R.Fabry, and M.Karels, "Networking Implementation Notes-4.4BSD Edition," June 1993.
[LT68] J.C.R.Licklider and R.Taylor, “The Computer as a Communication Device," Science and Technology, Apr. 1968.
[OIPSW] http://www.rfc-editor.org/rfcxx00.htm
[PO7] J.Pelkey, Entrepreneurial Capitalism and Innovation: A History of Computer Communications 1968-1988, available at http://historyofcomputercommunications.info
[P73] L.Pouzin, "Presentation and Major Design Aspects of the CYCLADES Computer Network," NATO Advanced Study Institute on Computer Communication Networks, 1973.
[RFCO871] M.Padlipsky "A Perspective on the ARPANET Reference Model," Internet RFC O871, Sept. 1982.
[RFCO959] J.Postel and J.Reynolds, “File Transfer Protocol,” Internet RFC O959/STD OOO9 0ct. 1985.
[RFC1122] R.Braden, ed., "Requirements for Internet Hosts-Communication Layers,″ Internet RFC 1122/STD OOO3, Oct. 1989.
[RFC1123] R.Braden, ed., "Requirements for Internet Hosts-Application and Support,″ Internet RFC l123/STD OOO3, Oct. 1989.
[RFC1812] F.Baker, ed., "Requirements for IP Version 4 Routers,″ Internet RFC 1812, June 1995.
[RFC3493] R.Gilligan, S.Thomson, J.Bound, J.McCann, and W.Stevens, "Basic Socket Interface Extensions for IPv6," Internet RFC 3493 (informational), Feb. 2003.
[RFC3542] W.Stevens, M.Thomas, E.Nordmark, and T.Jinmei, "Advanced Sockets Application Program Interface (API) for IPv6,″ Internet RFC 3542 (informational), May 2003.
[RFC3678] D.Thaler, B.Fenner, and B.Quinn, "Socket Interface Extensions for Multicast Source Filters," Internet RFC 3678 (informational), Jan. 2004.
[RFC3787] J.Parker, ed., "Recommendations for Interoperable IP Networks Using Intermediate System to Intermediate System (IS-1S)," Internet RFC 3787 (informational), May 2004.
[RFC4294] J.Loughney ed., "IPv6 Node Requirements," Internet RFC 4294 (informational), Apr. 2006.
[RFC4340] E.Kohler, M.Handley and S.Floyd, "Datagram Congestion Control Protocol (DCCP)," Internet RFC 4340, Mar. 2006.
[RFC4584] S.Chakrabarti and E.Nordmark, "Extension to Sockets API for Mobile IPv6,″ Internet RFC 4584 (informational),JuIy 2006.
[RFC4677] P.Hoffman and S.Harris, "The Tao of IETF-A Novice's Guide to the Internet Engineering Task Force,” Internet RFC 4677 (informational), Sept. 2006.
[RFC4960] R.Stewart, ed., "Stream Control Transmission Protocol," Internet RFC 4960, Sept. 2007.
[RFC5000] RFC Editor, "Internet official Protocol Standards," Internet RFC 5000/STD OOO1 (informational), May 2008.
[RFC5014] E.Nordmark, S.Chakrabarti, and J.Laganier, "IPv6 Socket API for Source Address Selection," Internet RFC 5014 (informational), Sept. 2007.
[RFC6250] D.Thaler, “Evolution of the IP Model,″ Internet RFC 6250 (informational), May 2011.
[SFR04] W.R.Stevens, B.Fenner, and A.Rudoff, UNIX Network Programming, Volume 1, Third Edition(Prentice Hall, 2004).
[SKYPE] http://www.skype.com
[SRC84] J.Saltzer, D.Reed, and D.Clark, "End-to-End Arguments in System Design,” ACM Transactions on Computer System, 2(4), Nov. 1984.
[WO2] M.Waldrop, The Dream Machine: J.C.R.Licklider and the Revolution That Made Computing Personal(Penguin Books, 1992).
[X85] Xerox Corporation, XeroX Network Systems Architecture--General Information Manual, XNSG O68504, 1985.
[Z80] H.Zimmermann, "OSI Reference Model-The ISO Model of Architecture for open systems Interconnection," IEEE Transactions on Communications, COM28(4), Apr. 1980.