Java 8 引入了 Stream 流式处理与 lambda 表达式,本文从 API 层面介绍相关使用。
区别总览
| 名称 | 参数 | 返回值 | 实例 |
|---|---|---|---|
| Consumer | 有 | 无 | Iterable上的forEach方法 |
| Function | 有 | 有 | Optional的map方法 |
| Predicate | 有 | 有(bool) | Optional的filter方法 |
| Supplier | 无 | 有 | 懒加载、惰性求值、Stream和generator(静态) |
详细解释
Supplier
在开发中,我们经常会遇到一些需要延迟计算的情形,比如某些运算非常消耗资源,如果提前算出来却没有用到,会得不偿失。在计算机科学中,有个专门的术语形容:惰性求值。惰性求值是一种求值策略,也就是把求值延迟到真正需要的时候。在Java里,我们有一个专门的设计模式几乎就是为了处理这种情形而生的:Proxy。不过,现在我们有了新的选择:Supplier。
简而言之,我们可以通过这个对象把耗资源运算放到get方法里,在程序里,我们传递的是Supplier对象,直到调用get方法时,运算才会执行,这就是所谓的惰性求值。
static void randomZero(Integer[] coins, Supplier<Integer> randomSupplier){
coins[randomSupplier.get()] = 0;
}
Integer[] coins = {10, 10, 10, 10, 10, 10, 10, 10, 10, 10};
randomZero(coins, () -> (int) (Math.random() * 10));
但是,通常实现Proxy模式,我们只会计算一次,反复计算是没有必要的。Guava给我们提供了一个函数:
Supplier<Object> memoize = Suppliers.memoize(new Supplier<Object>() {
@Override
public Object get() {
return null;
}
});
memoize()函数帮我们打点了前面所说的一些事情:第一次get()的时候,它会调用真正Supplier,得到结果并保存下来,下次再访问就返回这个保存下来的值。
有时候,这个值只咋一段时间内是有效的,Guava还给我们提供了另外一个函数,让我们可以设定过期时间;
expirableUltimateAnswerSupplier = memoizeWithExpiration(target, 100, NANOSECONDS);
Consumer
Consumer是一个函数式编程接口;Consumer意味着消费,即针对某个东西进行使用,因此它包含有一个输入而无输出的accept接口方法;
除accept方法,它还包含有andThen这个方法
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
可见这个方法就是指定在调用当前Consumer后是否还要调用其他的Consumer
public static void consumerTest() {
Consumer f = System.out::println;
Consumer f2 = n -> System.out.println(n + "-F2");
//执行完F后再执行F2的Accept方法
f.andThen(f2).accept("test");
//连续执行F的Accept方法
f.andThen(f).andThen(f).andThen(f).accept("test1");
}
Function
Function也是一个函数式编程接口;它代表的含义是“函数”,而函数经常是有输入和输出的,因此它含有一个apply方法,包含一个输入与输出;
除apply方法外,它还有compose与andThen及indentity方法。
/**
* Function测试
*/
public static void functionTest() {
Function<Integer, Integer> f = s -> s++;
Function<Integer, Integer> g = s -> s * 2;
/**
* 下面表示在执行F时,先执行G,并且执行F时使用G的输出当作输入。
* 相当于以下代码:
* Integer a = g.apply(1);
* System.out.println(f.apply(a));
*/
System.out.println(f.compose(g).apply(1));
/**
* 表示执行F的Apply后使用其返回的值当作输入再执行G的Apply;
* 相当于以下代码
* Integer a = f.apply(1);
* System.out.println(g.apply(a));
*/
System.out.println(f.andThen(g).apply(1));
/**
* identity方法会返回一个不进行任何处理的Function,即输出与输入值相等;
*/
System.out.println(Function.identity().apply("a"));
}
Predicate
Predicate为函数式接口,predicate的中文意思是“断定”,即判断的意思,判断某个东西是否满足某种条件;因此它包含test方法,根据输入值来做逻辑判断,其结果为True或者False。
/**
* Predicate测试
*/
private static void predicateTest() {
Predicate<String> p = o -> o.equals("test");
Predicate<String> g = o -> o.startsWith("t");
/**
* negate: 用于对原来的Predicate做取反处理;
* 如当调用p.test("test")为True时,调用p.negate().test("test")就会是False;
*/
Assert.assertFalse(p.negate().test("test"));
/**
* and: 针对同一输入值,多个Predicate均返回True时返回True,否则返回False;
*/
Assert.assertTrue(p.and(g).test("test"));
/**
* or: 针对同一输入值,多个Predicate只要有一个返回True则返回True,否则返回False
*/
Assert.assertTrue(p.or(g).test("ta"));
}
函数式编程接口的使用
通过Stream以及Optional两个类,可以进一步利用函数式接口来简化代码。
Java8的三个编程概念
- 流处理
- 从输入流中一个一个读取数据项,然后以同样的方式将数据项写入输出流
- 用行为参数化把代码传递给方法
- 即函数作为第一公民,可以作为值传递
- 并行与共享可变数据
Stream
Stream可以对多个元素进行一系列操作,也可以支持对某些操作进行并发处理。
Stream API和Collection API的行为差不多,但Collection API主要为了访问和存储数据,而Stream API主要用于描述对数据的计算。
经典的Java程序只能利用单核进行计算,流提供了多核处理数据的能力。但前提是传递给Stream API的方法不会互动(即有可变的共享对象)时,才能多核工作。
Lambda
Lambda表达式由参数列表、箭头和主体组成。
函数式接口
Java8新引入了函数式编程方式,大大提高了编码效率。首先要清楚一个概念:函数式接口;
它指的是有且只有一个未实现的方法的接口,一般通过FunctionalInterface这个注解来表名某个接口是一个函数式接口。函数式接口是Java支持函数式编程的基础。
注:哪怕有再多默认方法,只要接口中之定义了一个抽象方法,它仍然是函数式接口。
Lambda允许你直接以内联的形式为函数式接口的抽象方法提供实现,并把其作为函数式接口的实例。
FunctionalInterface注解
@FunctionalInterface用于表示该接口为函数式接口。如果它不是函数式接口的话,编译器将返回一个提示原因的错误。
@FunctionalInterface不是必须的,但最好为函数式接口都标注@FunctionalInterface.
函数描述符
函数式接口的抽象方法的基本签名 本质上就是Lambda表达式的签名。Java8将这种抽象方法叫做函数描述符。
Runnable接口的run方法即不接受任何参数也不返回,其函数描述符为:() -> void。该函数描述符代表了函数类别为空且返回void函数。
Scala、Kotlin等语言在其类型系统中提供显示的类型注释来描述函数的类型(即函数类型)
| 函数接口 | 函数描述符 | 基本类型特化 |
|---|---|---|
| Predicate |
T -> boolean | IntPredicate, LongPredicate, DoublePredicate |
| Consumer |
T -> void | IntConsumer, LongConsumer, DoubleConsumer |
| Function<T , R> | T -> R | IntFunction,IntToDoubleFunction, IntToLongFunction, ... , ToIntFunction,ToDoubleFunction ToLongFunction |
| Supplier |
() -> T | BooleanSupplier,IntSupplier, LongSupplier,DoubleSupplier |
方法引用
方法引用可以把现有方法像Lambda一样传递。
方法引用主要分三类:
- 指向静态方法的方法引用。(例如Integer的parseInt方法,写作Integer::parseInt)
- 指向任意类型实例方法的方法引用。(例如String 的length,写作String::length)
- 适用于对象作为Lambda表达式的一个参数
- 指向现存对象或表达式实例方法的方法引用
- 适用于调用现存外部对象的方法
- 适用于内部的私有方法
- 适用于调用现存外部对象的方法
注:构造函数、数组构造函数以及父类调用的方法引用形式比较特殊:
利用类名和关键字new来生成构造方法的方法引用。
-
对于默认构造函数,可以使用Supplier签名。
Supplier<Apple> c1 = Apple::new; //等价于 Supplier<Apple> c1 = () -> new Apple(); -
对于存在参数的构造方法,可根据参数情况寻找适合的函数式接口的签名。
Function<Integer, Apple> c2 = Apple::new; //等价于 Function<Integer, Apple> c2 = (weight) -> new Apple(weight);
3.6 流
从支持数据处理操作的源生成的元素序列——流
流允许以声明性方式处理数据集合。还可以透明地并行处理,无需写任何多线程代码。
- 流只遍历一次。遍历完之后,流就被消费了,需要重新从原始数据源那里再次获取一个新的流进行遍历。
- 只有触发终端操作,中间操作才会被执行。
- 中间操作一般都可以合并起来,在终端操作中一次性全部处理掉。
筛选
-
filter方法:接收一个谓词(一个返回boolean的函数)作为参数,并返回一个包括所有符合谓词的元素的流。
//输出结果:[1, 3, 0] List<Integer> numbers = Arrays.asList(1,3,8,6,0,7,5,6); number.stream() .filter(i -> i < 4) .collect(Collectors.toList()); -
dsitinct方法:依据流所生产元素的hashCode和equals方法,返回一个元素各异的流。(即返回一个没有重复元素的流)
//输出结果[2, 4] List<Integer> numbers = Arrays.asList(1,2,1,3,3,2,4); number.stream() .filter(i -> i % 2 == 0) .distinct() .collect(Collectors.toList());
流的切片
-
takeWhile方法:在第一个不符合要求的元素时停止处理。
//输出结果[1, 2, 3, 4] List<Integer> numbers = Arrays.asList(1,2,3,3,4,4,5,6); number.stream() .takeWhile(i -> i < 4) .collect(Collectors.toList()); -
dropWhile方法:在一个符合要求的元素时停止处理,并返回所有剩余的元素。
//输出结果:[4, 4, 5, 6] //在初始列表中的数据已排序(由高到低)的情况下: List<Integer> numbers = Arrays.asList(1,2,3,3,4,4,5,6); number.stream() //当发现第一个i < 4 为 true的元素时,则停止处理,并返回所有剩余的元素 .dropWhile(i -> i < 4) .collect(Collectors.toList()); -
limit方法:返回一个不超过给定长度的流。
- 如果流是有序的(如:源是List),则按顺序返回前n个元素。
- 如果流是无序的(如:源是set),则不会以任意顺序排序。
- 对于无限流,可以使用limit将其变成有限流。
//输出结果[1, 3]
List<Integer> numbers = Arrays.asList(1,3,8,6,0,7,5,6);
numbers.stream()
.filter(i -> i < 4)
//只返回前两个值
.limit(2)
.collect(Collectors.toList());
- shkip方法:返回一个扔掉前n个元素的流。
- 如果流中元素不足 n 个,则返回一个空流。
//输出结果[0]
List<Integer> numbers = Arrays.asList(1,3,8,6,0,7,5,6);
numbers.stream()
.filter(i -> i < 4)
//跳过前两个值
.skip(2)
.collect(Collectors.toList());
映射
-
map方法:将流中的每一个元素映射成一个新的元素。
//输出结果:[6, 2, 4, 1] List<String> languages = Arrays.asList("Kotlin", "Go", "Java", "C"); List<Integer> collect = languages.stream() //将String转为int .map(String::length) .collect(Collectors.toList()); -
flatMap方法:把一个流中的每一个值转换成另一个流,然后把所有流连接起来成一个流。
- 简单说就是:把流中的元素(如:列表,数组)化为新的流,或把流中的元素结合外部的列表(数组)化为新的流,再把新的流的元素整合到一个流中。
//输出结果:[K, o, t, l, i, n, G, J, a, v, C] List<String> languages = Arrays.asList("Kotlin", "Go", "Ja List<String> collect = languages.stream() .map(str -> str.split("")) //Arrays::stream 将 str.split("")返回的字符数组转化为流,再由flat //flatMap本质也是对流的元素进行转换(map也是对流的元素进行转换)。将流的元素转换成新的流 //等价于:flatMap(strArray -> Arrays.stream(strArray)) .flatMap(Arrays::stream) .distinct() .collect(Collectors.toList()); collect.stream().forEach(s -> System.out.print(s + ", "));练习:
List<Integer> numbers1 = Arrays.asList(1, 2, 3); List<Integer> numbers2 = Arrays.asList(3, 4); List<int[]> pairs = numbers1.stream() .flatMap(i -> numbers2.stream().map(j -> new int[]{i, j}) ).collect(Collectors.toList());
查找与匹配
-
anyMatch方法:检查流中是否至少有一个元素匹配给定的谓词。
//输出结果:true List<Integer> numbers = Arrays.asList(1,2,3,5,6,8); numbers.stream().anyMatch(i -> i > 3); -
allMatch方法:检查流中全部元素都匹配给定的谓词。
//输出结果:true List<Integer> numbers = Arrays.asList(1,2,3,5,6,8); numbers.stream().anyMatch(i -> i < 10); -
noneMatch方法:检查流中全部元素都不匹配给定的谓词。(与allMatch相对)
//输出结果:true List<Integer> numbers = Arrays.asList(1,2,3,5,6,8); numbers.stream().anyMatch(i -> i > 10); -
findAny方法:返回当前流中的任意元素。
//张三 17 List<User> users = Arrays.asList( new User("张三", 17), new User("张三", 18), new User("王五", 19)); Optional<User> u = users.stream() .filter(user -> user.getName().equals("张三")) .findAny(); -
findFirst方法:返回当前流中的第一个元素。
List<User> users = Arrays.asList( new User("张三", 17), new User("张三", 18), new User("王五", 19)); Optional<User> u = users.stream() .filter(user -> user.getName().equals("张三")) .findFirst();注:
- anyMatch、allMatch和noneMatch都属于终端操作。
- anyMatch、allMatch、noneMatch、findFirst和findAny不用处理整个,只要找到一个元素,就可以得到结果。
- findAny和findFirst同时存在的原因是并行。findAny在并行流中限制较少。
归约
将流中所有元素反复结合起来,从而得到一个值的查询,可以被归类为归约操作。(用函数式编程语言的术语来说,这成为折叠)。
reduce方法:接收Lambda将列表中的所有元素进行处理并归约成一个新值。
-
有初始值:
接收一个初始值和一个BinaryOperator
将两个元素结合起来产生一个新值。
T reduce(T identity, BinaryOperator<T> accumulator);
-
无初始值
一个BinaryOperator
将两个元素结合起来产生一个新值。
Optional<T> reduce(BinaryOperator<T> accumulator);
-
求和
List<Integer> numbers = Arrays.asList(1, 2, 3); Integer reduce = numbers.stream() //等价于reduce(0, (a,b) -> a + b) .reduce(0, Integer::sum); Optional<Integer> reduce1 = numbers.stream().reduce(Integer::sum); -
最大值
Optional<Integer> maxOptional = numbers.stream().reduce(Integer::max); -
最小值
Optional<Integer> maxOptional = numbers.stream().reduce(Integer::min);
数值流
原先的归约求和代码中,Integer::sum暗含装箱和拆箱的成本。Stream API提供了原始类型流特化,专门支持处理数值流的方法。Java8引入原始类型特化接口解决数值流拆箱与装箱的问题:IntStream、DoubleStream和LongStream,分别将流中的元素特化为int、long和double。
-
映射到数值流
mapToInt、mapToDouble和mapToLong用于将流转换为特化流:
List<Integer> numbers = Arrays.asList(1,2,3,4,5); int sum = numbers.stream().mapToInt(Integer::intValue).sum(); -
转换回对象流
当需要把原始流转换成对象流时(如:把int装箱回Integer),可以使用boxed。
List<Integer> numbers = Arrays.asList(1,2,3,4,5); IntStream intStream = numbers.stream().mapToInt(Integer::intValue); Stream<Integer> stream = intStream.boxed(); -
默认值OptionalInt
Optional也相应的提供原始类型特化版本:OptionalInt、OptionalLong和OptionalDouble。
List<Integer> numbers = Arrays.asList(1,2,3,4,5); OptionalInt maxNumber = numbers.stream().mapToInt(Integer::intValue).max();
数值范围
IntStream和LongStream提供产生生成数值范围的静态方法:range和rangeClosed。
range方法生成半闭区间(左闭右开),rangeClosed方法生成闭区间。
IntStream.range(1,100)
.filter(n -> n % 2 == 0)
.count();
构建流
-
由值创建流
静态方法Stream.of接收任意数量的参数,显示创建一个流。
Stream s = Stream.of("test"); Stream s1 = Stream.of("a","b","c");静态方法Stream.empty创建一个空流。
Stream stream = Stream.empty(); -
由数组或集合创建流
静态方法Arrays.stream将数组创建为一个流。
//asList只能用于包装类型,基本类型会变为List<int[]>对象 List<String> list = Arrays.asList(arr); //获取串行stream对象 Stream listStream = list.stream(); Arrays.stream(arr); //获取串行stream对象 Stream parallelListStream = list.parallelStream(); -
由文件生成流
java.nio.file.Files中很多静态方法会返回一个流,以便利用Stream API处理文件等I/O操作。
如:Files.lines返回一个由指定文件中的各行构成的字符串流:long uniqueWords = 0; //流会自动关闭,不需要额外try-finally操作 try { Stream<String> lines = Files.lines(Paths.get("data.txt"), Charset.defaultCharset()); uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" "))) .distinct() .count(); } catch (IOException e) { e.printStackTrace(); } -
由函数生成流:创建无限流
Stream API提供了两个静态方法用来从函数生成流:Stream.iterate()和Stream.generate(),不同于从集合创建的流,这两个静态方法创建的流没有固定的大小,成为无限流。
//since java1.8 public static <T> Stream<T> iterate(final T seed, final UnaryOperator<T> f); static<T> Stream<T> generate(Supplier<? extends T> s); //since java1.9 public static <T> Stream<T> iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> next);迭代:
itreate 方法接收一个初始值(种子)作为流的一个元素。再接收一个Lambda一次应用在每一个产生的新值上。
Stream.iterate(0, n -> n + 2) .limit(10) .forEach(System.out::println);java9对iterate方法进行增加,接受多一个谓词作为判断迭代调用何时终止。
IntStream.iterate(0, n -> n < 100, n -> n + 2) .forEach(System.out::println);也可以使用takeWhile对流执行短路操作(takeWhile函数Java9开始支持):
IntStream.iterate(0, n -> n + 2) .takeWhile(n -> n < 100) .forEach(System.out::println);生成
generate 接受一个Supplier
类型的Lambda提供新值。 Stream.generate(Math::random) .limit(5) .forEach(System.out::println);
用流收集数据
流支持两种类型的操作:中间操作 和 末端操作。
- 中间操作可以相互链接起来,将一个流转换为另一个流。中间操作不会消耗流,目的是建立一个流水线。
- 末端操作会消耗流,以产生一个最终结果。
归约和汇总
-
Collectors工厂类提供了很多归约的静态工厂方法。
-
Collectors.counting()用于统计总和。
long count = menu.stream().collect(collections.countiong()); -
Collectors.maxBy 和 Collectors.minBy用来计算流中的最大值和最小值。
//张三 17 List<User> users = Arrays.asList( new User("张三", 17), new User("张三", 18), new User("王五", 19)); Optional<User> collect = users.stream().collect( Collectors.maxBy( Comparator.comparingInt(User::getAge) ) ); -
同时Collectors类专门汇总提供了一些工厂方法类。
-
Collectors.summingInt、Collectors.summingLong和Collectors.summingDouble分别用于对int、long、double进行求和。
Integer collect1 = users.stream().collect(Collectors.summingInt(User::getAge)); -
Collectors.averagingInt、Collectors.averagingLong和Collectors.averagingDouble分别用于对int、long和double进行求平均值。
Double collect2 = users.stream().collect(Collectors.averagingInt(User::getAge)); -
Collectors.joining工厂方法会对流中每一个对象应用toString方法得到所有字符串连接成一个字符串。
String nameStr = users.stream().map(User::getName).collect(Collectors.joining());
-
-
分组
Collections的groupingBy()方法会把流中的元素分成不同的组。
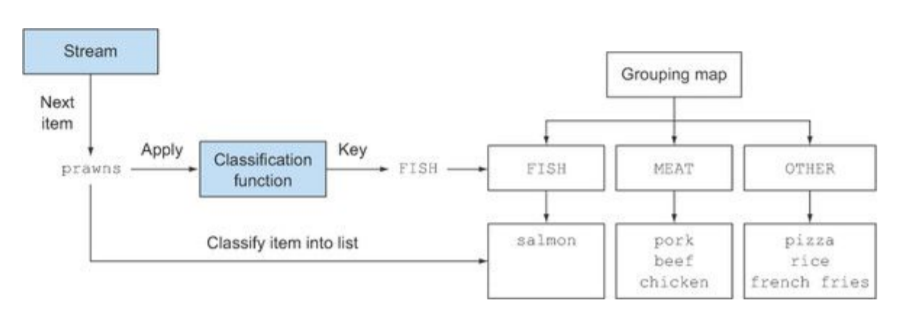
操作分组的元素
-
过滤
如果在groupingBy()之前,使用filter()对流进行过滤操作,可能会造成键的丢失。
例如:
存在以下Map:{ FISH = [prawns, salmon], OTHER = [french fries, rice], MEAT = [pork, beef, chicken]}如果在使用filter()后,再groupingBy()可能对某些键在结果映射中完全消失:
{ OTHER = [french fries, rice], MEAT = [pork, beef, chicken]}为此,Collectors类提供了filtering()静态工厂方法,它接受一个谓词对每一个分组中的元素执行过滤操作。最后不符合谓词条件的键将得到空的列表:
{FISH = [], OTHER = [french fries, rice], MEAT = [pork, beef, chicken]}Map<Dish.Type, List<Dish>> caloricDishesByType = menu.stream().collect( groupingBy(Dish::getType), filtering(dish -> dish.getCalories() > 500, toList()) )注:
使用重载的groupingBy()方法和filtering()方法:先分组再过滤;
先使用filter(),再使用groupingBy()方法:先过滤再分组。
-
映射
Collectors提供mapping静态工厂方法,接受一个映射函数和另外一个Collectors函数作为参数。映射函数将分组中的元素进行转换,作为参数的Collectors函数会收集对每个元素执行该映射函数的结果。
List<User> users = Arrays.asList( new User("张三", 17), new User("张三", 18), new User("王五", 19)); Map<String, List<String>> collect = users.stream().collect(groupingBy(User::getName, mapping(User::getName, toList()))); collect.forEach((k , v) -> { System.out.println("k = " + k); v.forEach(System.out::println); });Collectors工具类也提供了flatMapping,跟flatMap类似的功能。
多级分组
同时Collectors工具类也提供了可以嵌套分组的groupingBy,用于进行多级分组
注:
可以理解为在进行完第一次分组后,再对每一组元素进行再次分组。
groupingBy(f)(f是分类函数)实际上是groupingBy(f, toList())的简便写法。
List<User> users = Arrays.asList(
new User("张三", 17),
new User("张三", 18),
new User("王五", 19));
Map<String, Map<String, List<User>>> collect = users.stream().collect(
groupingBy(
User::getName,
groupingBy(us -> {
if (us.getAge() >= 18) {
return "大于等于18";
} else if (us.getAge() < 18) {
return "小于18";
} else {
return "未知";
}
}
)
)
);
collect.forEach((k , v) -> {
System.out.println("k = " + k);
v.forEach((k1 , v1) -> {
System.out.println(k1);
v1.forEach(user -> System.out.println(user.getName()));
});
});
按子组收集数据
groupingBy()的第二个收集器可以是任何类型。例如可以使用counting()收集器作为它的第二个参数,统计分组的数量:
List<User> users = Arrays.asList(
new User("张三", 17),
new User("张三", 18),
new User("王五", 19));
Map<String, Long> collect = users.stream().collect(
groupingBy(User::getName, counting())
);
collect.forEach((k , v) -> {
System.out.println("k = " + k);
System.out.println("v = " + v);
});
得到{ "张三" = 2, "王五" = 1 }
List<User> users = Arrays.asList(
new User("张三", 17),
new User("张三", 17),
new User("王五", 19));
Map<Integer, User> collect = users.stream().collect(
groupingBy(
User::getAge,
collectingAndThen(
//maxby返回的是Optional类型对象
maxBy(Comparator.comparingInt(User::getAge)),
//当找到最大值后,会执行get操作
Optional::get
)
)
);
如果users中没有某个年龄,该类型不会对应一个Optional.empty()值,而且根本不会在Map的键中。所以转换函数Optional::get的操作是安全的。
分区
Collectors工具类提供partitionedMenu()静态工厂函数来实现分区,分区是分组的特殊情况。由谓词作为分类函数,这意味着得到的分组Map的键类型是Boolean,最多分为true和false两组。
Map<Boolean, List<User>> collect = users.stream().collect(
partitioningBy(
u -> u.getAge() > 18
));
同时,partitionedMenu()也和groupingBy()类似,可以进行二级分区。
收集器接口
public interface Collector<T, A, R>{
//创建一个空的累加器
Supplier<A> supplier();
//将元素添加到结果容器
BiConsumer<A, T> accumulator();
//合并两个结果(定义了对流的各个子部分进行并行处理时,各个子部分归约所得的累加器如何并行)
BinaryOperator<A> combiner();
//对结果容器应用最终转换
Function<A, R> finisher();
//定义收集器的行为
Set<Characteristics> characteristics;
}
泛型的定义如下:
- T表示流中要收集的项目的泛型。
- A表示累加器的类型。(累加器是收集过程中用于累积部分结果的对象)
- R表示收集操作得到的对象的类型。
以ToListCollector为例
public class ToListCollector<T> implements Collector<T, List<T>, List<T>> {
public ToListCollector(){}
//创建ArrayList对象作为累加器
public Supplier<List<T>> supplier(){
return ArrayList::new;
}
//利用add函数将流中的元素添加到列表中
public BiConsumer<List<T>, T> accumulator(){
return List::add;
}
//两个累加器(即两个ArrayList对象)进行相加
public BinaryOperator<List<T>> combiner(){
return (list, list2) -> {
list.addAll(list2);
return list;
};
}
//累加器进行最终的转换
public Function<List<T>, List<T>> finisher(){
//Function.identity()表示给什么返回什么,也就是不进行转换
return Function.identity();
}
//定义收集器的行为
public Set<Characteristics> characteristics(){
return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH, Characteristics.CONCURRENT));
}
}
Characteristics的三个枚举:
- UNORDERED——归约结果不受流中项目的遍历和累积顺序的影响。
- CONCURRENT——accumulator函数可以从多个线程同时调用,且该收集器可以并行归纳流。(仅仅只是数据源无序时才会并行处理)
- IDENTITY_FINISH——表明完成器方法返回的函数是一个恒等函数,可以跳过。累加器对象会直接用作归约过程的最终结果。这也意味着,将累加器A不加检查的转换为结果R是安全的。
进行自定义收集,而不去实现Collector
对于IDENTITY_FINISH的收集操作,Stream重载的collect方法接收三个函数——supplier、accumulator和combiner。该collect方法创建的收集器的Characteristics永远是Characteristics.IDENTITY_FINISH和Characteristics.CONCURRENT。
ArrayList<Object> collect = users.stream().collect(
//创建累加容器
ArrayList::new,
//将流元素添加到累加容器中
List::add,
//合并累加容器
List::addAll
);
并行数据处理与性能
- 对顺序流调用parallel()方法并不意味着流本身有任何实际的变化,它仅仅在内部设置了一个boolean标志,表示你想让调用parallel()之后的所有操作都并行执行。对并行流调用sequential方法就可以把它变成顺序流。
- 并行流默认的线程数量等于你处理器的核数。
使用并行流时,考虑以下因素:
- 留意自动装箱和拆箱。(应尽量将其转为原始类型流)
- 对于较小数据量,无需使用并行流。
- 考虑流背后的数据结构是否容易分解。
- 部分操作本身在并行流上的性能比顺序流差。如limit和findFirst
- 考虑合并步骤的代价是大是小。
- 考虑操作流水线的总操作成本。当单个元素通过流水线的成本较高时,使用并行流比较好。
流的数据源和可分解性:
| 源 | 可分解性 |
|---|---|
| ArrayList | 差 |
| LinkedList | 差 |
| IntStream.range | 极佳 |
| Stream.iterate | 差 |
| HashSet | 好 |
| TreeSet | 好 |
Collection API的增强功能
Arrays.asList()创建一个固定大小的列表,列表的元素可以更新,但不可以增加或删除。
Java9引入以下工厂方法:
-
List.of——创建一个只读列表,不可set、add等操作。
-
Set.of——创建一个只读的Set集合。
-
Map.of——接受的列表中,以键值交替的方式创建map的元素。
-
当创建Map的键值对过多时,可以使用map.ofEntries()和Map.entry()来创建map。
Map.ofEntries( entry("zhangsan", 10), entry("lisi", 12), );
-
重载与变参
在 Java API中,List.of包含多个重载版本:
static <E> List<E> of(E e1);
static <E> List<E> of(E e1, E e2);
而不提供变参版本是因为需要额外的分配一个数组,这个数组被封装与列表中。使用变参版本的方法,就要负担分配数组、初始化以及最后进行垃圾回收的开销。(如果元素数量超过10个,实际调用的还是变参方法。)
使用List、Set和Map
-
removeIf——移除集合中匹配制定谓词的元素。(该方法由Collection接口提供默认方法,List和Set都可用)
default boolean removeIf(Predicate<? super E> filter)- 当使用for-each遍历列表,进行移除操作时,会导致ConcurrentModificationException。因为遍历使用的迭代器对象和集合对象的状态同步。我们只能显示调用迭代器对象(Iterator对象)的remove方法。因此Java8提供removeIf方法, 安全简便的删除符合谓词的元素。
-
replaceAll()——使用一个函数替换List或Map中的元素。(该方法由List接口提供默认方法)
default void replaceAll(UnaryOperator<E> operator)-
该函数只是在列表内部进行同类型的转换,并没有创建新的列表。也就是说初始为List
,函数执行完还是List 。 -
default void replaceAll(BiFunction< ? super K, ? super V, ? extends V> function)
-
-
sort()——对列表自身进行排序。(该方法由List接口提供默认方法)
default void sort(Comparator<? super E> c) -
forEach——List和Set,甚至是Map在Java8中都支持forEach方法。而遍历提供的便捷,特别是Map的遍历。
default void forEach(Consumer<? super T> action) default void forEach(BiConsumer<? super K, ? super V> action) -
Entry.comparingByValue()和Entry.comparingByKey()——对Map的值或键进行排序。
-
Map.compute——使用指定的键计算新的值,并将其存储到Map中,并返回新值。(指定一个key,再提供一个BiFunction,依据key和旧值,计算新值。如果新值为null,则不会加入到Map中并将旧值移除。)
default V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) -
Map.computeIfAbsent——如果指定的键没有对应的值(没有该键或该键对应的值是空),使用该键计算新的值,并添加到Map中(如果新值为null,则不会加入到Map中并将旧值移除。),并返回新值。
default V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)- 该方法对值需要初始化时有用。比如Map<K, List
>添加一个元素(初始化对应的ArrayList,并返回该值):
map.computeIfAbsent("daqi", name -> new ArrayList<String>().add("Java8")); - 该方法对值需要初始化时有用。比如Map<K, List
-
Map.cumputeIfPresent——如果指定的键在Map中存在,依据该键的旧值计算该键的新值,并将其添加到Map中。(如果新值为null,则不会加入到Map中,并将旧值移除。)
default V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) -
Map.remove——重载版本的remove可以删除Map中某个键对应某个特定值的映射对。(即key和value都匹配上,才从Map中移除)
default boolean remvoe(Object key, Object value) -
Map.merge——如果指定的键在Map中存在,依据该键和旧值计算该键的新值,并将其添加到Map中;如果指定的键在Map中不存在,依据指定的value作为key的值,并将其添加到Map中。
default V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction)- 该函数可用于Map 的合并,或用于将Collector转换成Map。
Map<String, Integer> languages = new HashMap(); languages.put("Java", 8); languages.put("kotlin", 1); HashMap<String, Integer> languages2 = new HashMap(); languages2.put("Java", 11); languages2.put("Go", 1); languages.forEach((k , v) -> { if (v != null) { languages2.merge(k, v, Integer::sum); } });List<User> users = Arrays.asList( new User("张三", 17), new User("张三", 17), new User("王五", 19)); Map<String, Integer> collect = users.stream().collect(toMap(User::getName, User::getAge, Integer::sum));
重构
改善代码可读性
-
用lambda表达式取代匿名类
-
匿名类和lambda表达式中的this和super的含义不同。在匿名类中,this代表的是类自身;在lambda表达式中,this代表的是包含类。
-
匿名类可屏蔽包含类的变量,而lambda表达式不能(编译报错)
int a = 10; //lambda 表达式 Runnable r1 = () -> { //报错,提示:改变了已在作用域中被定义 int a = 1; }; //匿名类 Runnbale r2 = new Runnable(){ @Override public void run(){ //编译正常 int a = 2; } } -
匿名内部类的类型是在初始化时确定的,lambda的类型取决于它的上下文。当出现两个或以上方法参数的函数描述符与lambda的函数描述符匹配时,需要显式的类型转换来解决。
interface daqiRunnable{ public void action(); } //无论Runnbale还是daqiRunnable,其函数描述符为() -> void public static void doSomething(Runnable r){} public static void doSomething(daqiRunnable r){} public static void main(String[] args){ //显示类型转换 doSomething((daqiRunnable) () -> {} ); }
-
-
用方法引用重构lambda表达式,提高代码的可读性。
-
将较复杂的Lambda逻辑封装在方法中,使用方法引用代替该Lambda。
-
尽量使用静态辅助方法。比如:comparing和maxBy
list.sort((a1, a2) -> a1.getWeight().compareTo(a2.getWeight())); //替换成 list.sort(Comparator.comparing(Apple::getWeight)); -
很多通用的归约操作,都可以借助Collectors的辅助方法 + 方法引用代替。
list.stream().map(Dish::getCalories) .reduce(0, (c1,c2) -> c1 + c2); //替换成 list.stream() .collect(summingInt(Dish::getCalories));
-
-
用Stream API重构命令式的数据处理