摘要
在 J2SE1.5 的 java.util.concurrent包(下面简称为 j.u.c 包 )中,大多数的同步器(例如锁、栅栏等。)都是使用基于 AbstractQueuedSynchronizer类(下面简称为 AQS 类),这个简单的小型框架构建的。这个框架提供了原子管理同步状态、线程的阻塞和解除阻塞、以及排队的通用机制。本文描述了该框架的基本原理、设计、实现、使用和性能。
类别和主题描述符
D.1.3 [编程技术]:并发编程 —— 并行编程
一般术语
算法、策略、性能、设计。
关键字
同步,Java
1. 介绍
JavaTM 发布版本 J2SE-1.5 引入了 j.u.c 包,这是通过 JCP (Java社区进程)的 JSR(Java规范请求)166 规范创建的,这个包提供了支持中等并发成都的并发类合集。这些组件包括一组同步器——维护内部同步状态(例如,表示锁的状态是获取还是释放)的抽象数据类型(ADT)类、更新和检查该状态的操作。以及至少会有一个方法会导致调用现存在同步状态被获取时阻塞,并在其他线程更改同步状态时解除阻塞。实例包括各种形式的互斥锁、读写锁、信号量、屏障、Future、时间指示器和传送队列等(exclusion locks, read-write locks, semaphores, barriers, futures, event indicators, and handoff queues)。
众所周知,几乎任何同步器都可以用于实现其他形式的同步器。例如,可以用可重入锁实现信号量,反之亦然。然而,这样做通常会增加复杂性、开销和不灵活性,使其至多只能是个二流工程。且缺乏吸引力。此外,它在概念上没有吸引力。如果任何这样的构造方式不能在本质上比其他形式更简洁,那么开发者就不应该随意地选择其中的某个来作为基础构建另一个同步器。取而代之,JSR166 建立了一个以 AQS 类为中心的小型框架,它为用户自定构造器以及j.u.c 包中大多数提供的同步器提供了一种通用的机制。
本文的其余部分将讨论该框架的需求、设计和实现背后的主要思想、示例用法以及一些性能指标的测量。
2 需求
2.1 功能
同步器有一般包含两种方法:一种是 acquire 操作 ,用于阻塞调用的线程,除非/直到同步状态允许它继续;另一种是 release 操作,用于通过某种方式改变同步状态,以允许一个或多个被 acquire 的线程解除阻塞。
j.u.c 包没有为同步器定义一个统一的 API。有些是通过公共接口定义的(例如,Lock),而另外一些则定义了其特有的版本。因此,在不同的类中,acquire 和 release 操作的名字和形式会有不同。例如:Lock.lock、Semaphore.acquire、CountDownLatch.await 和 FutureTask.get,在这个框架里,这些方法都是 acquire 操作。但是,j.u.c包确实保持了跨类的一致约定,以支持一系列常见的使用选项。如果有意义,每个同步器都支持以下操作:
- 非阻塞同步尝试(例如,
tryLock)以及阻塞版本。 - 可选超时,因此应用程序可以放弃等待。
- 通过中断实现任务取消,通常分为可取消的
acquire版本和不可取消的acquire版本。
同步器可能根据它们是否管理 exclusive 状态 (一次只有一个线程可以通过阻塞点)和可能的 shared 状态(多个线程至少在某些情况下可以继续)而有所不同。当然,常规的锁类往往只维护 exclusive 状态,但是计数信号量在数量许可的情况下,允许多个线程同时执行。为了使框架使用能够更加广泛,这两种模式都要支持。
j.u.c 包还定义了 Condition 接口,用于支持监控形式的 await/singal 操作,这些操作可能与独占的 Lock 类相关联,并且其本质上与其相关 Lock 类交织在一起。
2.2 性能目标
Java 内置锁(使用 synchronized 的方法或代码块)的性能问题长期以来一直被人们关注,有关它们的构造有相当多的文献(例如,[1]、[3] )。然而,大部分的研究主要关注的是在单核处理器上,大部分时间使用与单线程上下文环境中,如何尽量降低其空间(因为任何 Java 对象都可以充当锁)和时间的开销。对于同步器来说,这两个都不是特别重要的问题:程序员仅在需要的时候才会使用同步器,因此并不需要压缩空间来避免浪费,并且同步器几乎只用于多线程设计(特别是在多核处理器上),在这种设计下,偶尔的竞争是在意料之中的。因此,常规的 JVM 锁优化策略主要是针对零竞争的场景,而其他场景则使用缺乏可预测的”慢速路径(slow paths)“[12],对于严重依赖 j.u.c 的典型多线程服务器应用程序来说,这不是正确的策略选择。
相反,这里的主要性能目标是可伸缩性:即使在同步器发生竞争的情况下,也要可预测地保持效率。理想情况下,不管有多少线程试图通过同步点,通过同步点所需的开销应该是恒定的。其中一个主要目标是,在某一线程被允许通过同步点但还没有通过的情况下,使其耗费的总时间最少。但是,者必须与资源考虑相平衡,包括总的 CPU 时间需求、内存流量和线程调度开销。例如,自旋锁通常比阻塞锁所需要的时间更短,但是通常也会浪费 CPU 时钟周期,并且造成内存竞争,因此通常不适用。
实现同步器的这些目标包含了两种不同的使用类型。大多数应用程序应该最大限度地提高总吞吐量和容错性,并且最好保证尽量减少接的情况。然而,对于那些控制资源分配的程序来说,更重要的是去维持多线程读取的公平性,可以接受较差的总吞吐量。没有框架能够代表用户在这些冲突的目标之前做出决定;相反,必须适应不同的公平策略。
无论同步器内部设计得多么好,在某些应用程序中都会产生性能瓶颈。因此,框架必须能够监控和检查基本操作,以允许用户发现和缓解瓶颈。这至少(也是最有用的)需要提供一种方法来确定有多少线程被阻塞。
3. 设计和实现
同步器背后的基本思想非常简单。acquire 操作如下:
while(synchronization state does not allow acquire) {
enqueue current thread if not already queued;
possibly block current thread;
}
dequeue current thread if it was queued;
release 操作如下:
update synchronization state;
if(state may permit a blocked thread to acquire)
unblock one or more queued threads;
为了支持上述操作,需要下面三个基本组件相互协作:
- 同步状态的原子性原理;
- 线程的阻塞与解除阻塞;
- 队列的管理;
也许可以创建一个框架,允许这三个部分各自独立变化。然而,这既不高效也不实用。例如,保存在队列节点中的信息必须与解除阻塞所需要的信息一致,而暴露出的方法签名必须依赖于同步状态的特性。
同步器框架中的核心设计决策是这三个组件选择一个具体实现,同时在使用方式上仍然有大量的选择可用。这有意地限制了其适用范围,但是提供了足够的效率,是的实际上没有理由在合适的情况下不用这个框架而去重新造一个。
3.1 同步状态
AQS类仅使用单个 int(32 bit)来保存同步状态,并暴露出 getState、setState 以及 compareAndSet 操作来读取和更新这个状态。这些方法都依赖于 java.util.concurrent.atomic 支持,这个包提供了兼容 JSR133 中 volatile 在读和写上的语义,并且通过使用本地的 compare-and-swap 或 load-linked/store-conditional 指令来实现 compareAndSetState,只有当它持有给定的期望值时,才会自动将状态设置为给定的新值。
将同步状态限定为 32 位 int 是出于实践上的考量。虽然 JSR166 也提供了 64 位 long 字段的原子操作,但是这些操作在很多平台上还是使用内部锁的方式来模拟实现的,以至于会使同步器的性能不佳。将来,很可能会添加第二个基类,专门用于 64 位状态(使用 long 控制参数)。然而,现在还没有一个令人信服的理由将其纳入计划。目前,32 位足以满足大多数应用,只有一个 j.u.c 同步器类 CyclicBarrier 需要更多的位来维护状态,所以它使用了锁(该包中大多数更高层次的 工具也是如此)。
基于 AQS 的具体类必须根据这些暴露出的状态相关的方法定义 tryAcquire 和 tryRelease 方法,以控制 acquire 和 release 操作。当同步状态满足时,tryAcquire 方法必须返回 true,而当新的同步状态允许后续 acquire 时,tryRelease 方法也必须返回 true。这些方法都接受一个 int 类型的参数,该参数可用于传递想要的状态。例如:可重入锁,当某个线程从条件等待中返回,然后重新获取锁时,为了重新建立循环计数的场景。很多同步器并不需要这样的参数,因此忽略它即可。
3.2 阻塞
在 JSR166 之前,除了创建基于内置监视器的同步器,没有 Java API 可以阻塞和解锁线程。唯一可以选择的是 Thread.suspend 和 Thread.resume,但是它们都有无法解决的竟态问题,所以也没办法使用:当一个非阻塞线程在一个正准备阻塞的线程调用 suspend 之前调用 resume,resume操作将不起作用。
java.util.concurrent.locks 包包含一个 LockSupport 类,其中包含解决这个问题的方法。方法 LockSupport.park 阻塞当前线程,除非或直到发出 LockSupport.unpark(虚假唤醒也是允许的) 。对 unpark 的调用是不 ”计数“的,所以一个 park 之前的多个 unpark 只会解除一个 park 操作。此外,这适用于每个线程,而不是每个同步器。一个线程在一个新的同步器上调用 park 操作可能会立即返回,因为在此之前可能有“剩余的” unpark 操作。但是,在缺少一个 unpark 操作时,下一次调用 park 就会阻塞。虽然可以显式地消除这个状态,但并不值得这样做。在需要的时候多次调用 park 会更高效。
这个简单的机制在某种程度上类似于 Solaris-9 的线程库 [11],WIN32的 “可消费事件”,以及 Linux 中的 NPTL 线程库,因此最常见的运行 Java 的平台上都有相对应的有效实现,(但目前 Solaris 和 Linux 上的 Sun Hotspot JVM 参考实现实际上是使用一个 pthread 的 condvar 来适应目前的运行时设计的)。park 方法同样支持可选的相对或绝对的超时设置,以及与 JVM 的 Thread.interrupt 结合 —— 可通过中断来 unpark 一个线程。
3.3 队列
整个框架的核心是维护阻塞线程的队列,这里仅限于 FIFO 队列。因此,该框架不支持基于优先级的同步。
如今,对于同步队列最合适的选择是不需要使用低级锁来构造的非阻塞数据结构,这一点几乎没有争议。其中,有两个主要的候选:一个是 Mellor-Crummey 和 Scott锁(MCS锁)[9] 的变体,另一个是Craig,Landin 和 Hagersten锁(CLH锁)[5] [8] [10]的变体。一直以来,CLH 锁只用于旋转锁。然而,它们似乎比 MCS 更适合在同步框架器中使用,因为它们更容易处理取消和超时,所以作为实现的基础。最终的设计与最初的 CLH 结构相差甚远,因此下文将对此做出解释。
CLH 队列实际上并不是很像队列,因为它的入队和出队操作都与它的用途(即用作锁)紧密相关。他是一个链表队列,通过两个字段 head 和 tail 来存取,这两个字段支持原子更新,两者在初始化时都指向了空节点。
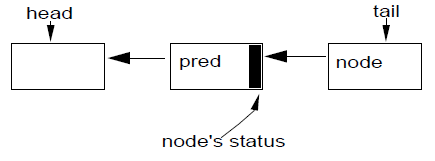
一个新节点,node,通过一个原子操作入队:
do {
pred = tail;
} while (!tail.compareAndSet(pred, node));
每一个节点的 release 状态都保存在其前驱节点中。因此,自旋锁的“自旋”操作如下:
while (pred.status != RELEASED); // spin
自旋后的出队操作只需将 head 字段指向刚刚得到锁的节点:
head = node
CLH 锁的优点之一是:其入队和出队操作是快速的、无锁的、无阻塞的(即使在竞争情况下,也只会有一个线程赢得插入机会,从而能继续进行);检测是否有线程在等待也很快(只需要检测 head 和 tail 是否相等);同时,release 是分散的,避免了一些不必要的内存竞争。
在 CLH 锁的原始版本中,节点之间甚至都没有链接。在自旋锁中,pred 变量可以作为局部变量保存。然而,Scott 和 Scherer [10] 证明,通过在节点中显式的维护 pred 字段,CLH 锁可以处理超时和各种形式的取消:如果节点的前驱结点取消,节点可以滑动去使用前一个节点的状态字段。
使用 CLH 队列阻塞同步器,需要做的主要修改是提供一种高效的方式定位某个节点的后继节点。在自旋锁中,一个节点只需要改变其状态,下一次自旋中其后继节点就能注意到这个改变,所有节点间的链接操作并不是必须的。但是在阻塞同步器中,一个节点需要显式地唤醒(unpark)其后继节点。
AQS 队列的节点包含一个 next 链接到它的后继节点。但是,由于没有针对双向链表节点的类似 compareAndSet 的原子性无锁插入指令,因此这个 next 链接的设置并非作为原子性插入操作的一部分,而仅是在节点被插入后简单赋值:
pred.next = node;
这反映在所有的用法中。next 链接仅是一种优化。如果一个节点的后继节点通过它的 next 字段看起来不存在(或看起来被取消了),总是可以从尾部开始,使用 pred 字段向前遍历来检查是否真的有后继节点。
第二组修改是使用保存在每个节点中的状态字段来控制阻塞,而非自旋。在同步器框架中,仅在线程调用具体子类的 tryAcquire 方法返回 true 时,队列中的线程才能从 acquire 操作中返回;而单个 release 位是不够的。但是仍然需要控制,以确保活动线程只允许在队列的头部调用 tryAcquire;在这种情况下,acquire 可能会失败,然后(重新)阻塞。这种情况不需要读取状态标识,因为可以通过检查当前节点的前驱是否为 head 来确定权限。与自旋锁不同,这里会读取 head 的副本以保证不会有太多的内存竞争。但是,取消状态必须仍然存在于状态字段中。
队列节点的状态字段还用于避免不必要的 park 和 unpark 调用。虽然这些方法相对于阻塞原语来说比较快,但是它们在跨 Java 和 JVM 运行时和/或操作系统边界时仍有可避免的开销。在调用 park 之前,线程设置一个 “唤醒(signal me)” 位,然后再次检查同步和节点状态。一个释放的线程会清空其自身状态。这样线程就不必频繁地尝试阻塞,尤其对于锁类,在这些锁类中,等待下一个合格线程获取锁的时间会加重其他竞争。除非后继线程已经设置了 signal 位,否则这也可以避免正在 release 的线程去判断其后继节点。这也消除了除非 signal 和 cancel 一起发生,否则必须遍历多个节点来处理明显为空的 next 字段的情况。
同步器框架中使用的 CLH 锁的变体与其他语言中使用的变体之间的主要区别可能是,依靠垃圾收集来挂你节点的存储回收,这避免了复杂性和开销。然而,即使依赖 GC,也仍然需要在确定链接字段永远不会被需要时,将其置为 null。这往往可以与出队操作一起完成。否则,无用的节点仍然可达,就导致它们不可回收。
J2SE1.5 版本的源代码文档中描述了一些更进一步的微调,包括 CLH 队列在第一次争用时所需的初始空节点的延迟初始化等。
抛开这些细节,基本的 acquire 操作的最终实现的一般形式如下(互斥,非中断,无超时):
if (!tryAcquire(arg)) {
node = create and enqueue new node;
pred = node's effective predecessor;
while (pred is not head node || !tryAcquire(arg)) {
if (pred's signal bit is set)
park()
else
compareAndSet pred's signal bit to true;
pred = node's effective predecessor;
}
head = node;
}
release 操作:
if (tryRelease(arg) && head node's signal bit is set) {
compareAndSet head's signal bit to false;
unpark head's successor, if one exists
}
acquire 操作的主循环次数依赖于具体实现类中 tryAcquire 的实现方式。另一方面,在没有 cancel 操作的情况下,每一个组件的 acquire 和 cancel 都是在一个 O(1) 常数时间内操作,不考虑 park 中发生的所有操作系统线程调度。
支持 cancel 操作主要是要在 acquire 循环里的 park 返回时检查中断或超时。由于超时或中断而被取消等待的线程会设置其节点状态,然后 unpark 其后继节点。在有 cancel 的情况下,判断其前驱结点和后继节点以及重置状态可能需要 O(n) 的遍历(n 是队列的长度)。由于 cancel 操作,该线程再也不会被阻塞,节点的连接和状态字段可以被快速重建。
3.4 条件队列
同步器框架提供了一个 ConditionObject 类,给维护独占同步的类以及实现 Lock 接口的类使用。一个锁对象可以管理任意数量的 ConditionObject,可以提供典型的监视器风格的 await、signal 和 singalAll 操作,包括那些带有超时的操作,以及一些检测和监控的方法。
同样是通过修正一些设计决策,ConditionObject 类使条件能够与其他同步操作有效地集成。该类仅支持 Java 风格的监视器访问规则,在这些规则中,只有当拥有条件的锁被当前线程持有时,条件操作才是合法的(参见 [4] 对替代方法的讨论)。因此,一个 ConditionObject 关联到一个 ReentrantLock 上就表现的跟内置监视器的行为方式相同(通过 Object.await 等),不同之处仅在与方法名、额外的功能以及用户可以为每个锁声明多个条件。
ConditionObject 使用与同步器相同的内部队列节点,但在单独的条件队列中维护它们。signal操作是通过将节点从条件队列转移到锁队列中来实现的,而没有必要在需要唤醒的线程重新获取到锁之前将其唤醒。
基本的 await 操作如下:
create and add new node to condition queue;
release lock;
block until node is on lock queue;
re-acquire lock;
signal 操作如下:
transfer the first node from condition queue to lock queue;
因为这些操作仅在持有锁时执行,所以它们可以使用顺序链表队列操作(在节点中使用 nextWaiter 字段)来维护条件队列。转移操作仅仅把第一个节点从条件队列中的链接移除,然后通过 CLH 插入操作将其插入到锁队列上。
实现这些操作的主要复杂性是处理由于超时或 Thread.interrupt 而导致的条件等待的取消。cancel 和 signal几乎同时发生就会有竞争问题,最终的结果遵照内置监视器的规范。JSR133 修订后,就要求如果中断发生在 signal 操作之前,await 方法必须在重新获取到锁后,抛出 InterruptedException。但是,如果中断发生在 signal 后,await 必须返回且不抛异常,同时设置线程的中断状态。
为了保持正确的顺序,队列节点状态变量中的一个位记录了该节点是否已经(或正在)被转移。cancel 和 signal 相关的代码都会尝试用 compareAndSet 修改这个状态。如果某次 signal 操作修改失败,就会转移队列中的下一个节点(如果存在的话)。如果某次 cancel 操作修改失败,就必须终止此次转移,然后等待重新获得锁。后面的情况采用了一个潜在的无限的自旋等待。在节点成功的被插入到锁队列之前,被 cancel 的等待不能重新获得锁,所以必须自旋等待 CLH 队列插入(即 compareAndSet )成功,被 signal 线程成功执行。这里很少需要自旋,并且使用 Thread.yield 来提供一个调度提示其他线程(理想情况下是发出 signal 的线程)应该运行。虽然在这里可以为 cancel 实现一个帮助策略来插入节点,但是这种情况非常罕见,以至于无法证明这样做所带来的额外开销是合理的。在所有其他情况下,这里和其他地方的基本机制不使用自旋或yield,在因此在但处理器上保持了合理的性能。
4. 用例
AQS 类将上述功能组合在一起,并作为同步器的“模板方法模式”[6]基类。子类只需定义状态的检查和更新的相关方法,实现控制 acquire 和 release 操作。然而,AQS 的子类本身用作同步器 ADT 并不合适,因为该类必须暴露出内部内部控制 acquire 和 release 的规则,这些都不应该对用户可见。所有 j.u.c 包中的同步器类都声明了一个 private 且继承 AQS的内部类,并且把所有同步方法都委托给这个内部类。这样,各个同步器类的公开方法就可以使用适合自己的名称。
例如,这里有一个最简单的 Mutex 类,它使用同步状态 0 表示未锁定,使用同步状态 1 表示锁定。这个类不需要同步方法中的参数,因此这里在调用的时候使用 0 作为实参,方法实现里将其忽略。
class Mutex {
class Sync extends AbstractQueuedSynchronizer {
public boolean tryAcquire(int ingore) {
return compareAndSetState(0, 1);
}
public boolean tryRelease(int ignore) {
setState(0);
return true;
}
}
private final Sync sync = new Sync();
public void lock(){
sync.acquire(0);
}
public void unlock(){
sync.release(0);
}
}
这个例子的完整版本,以及其他使用指南可以在 J2SE 文档中找到。还有可以有一些其他变体。例如,tryAcquire 可以使用 “test-and-test-and-set” 策略,即在改变状态值之前先对状态进行校验。
令人诧异的是,像互斥锁这样对性能敏感的东西,也打算通过委托和虚方法结合的方式来定义。然而,这正是现代动态编译器长期关注的面向对象设计结构。它们往往擅长优化掉这种开销,起码会优化频繁调用同步器的哪些代码。
AQS 类还提供了许多方法来帮助同步器类进行策略控制。例如,基础的 acquire 方法有可超时和可中断的版本。虽然到目前为止的讨论都集中在独占模式的同步器上(如锁),但 AQS 类也包含一组并行的方法(如acquireShared),不同之处在于 tryAcquireShared 和 tryReleaseShared 方法可以通知框架(同步它们的返回值)可以接受更多的请求,最终框架会通过级联的 signal 唤醒多个线程。
虽然序列化(持久存储或传输)同步器通常来说没有太大意义,但这些类经常被用来构造其他类,如线程安全的集合,它们通常是可序列化的。AQS 和 ConditionObject 类提供了序列化同步状态的方法,但不会序列化潜在的被阻塞的线程,也不会序列化其他内部暂时性的 bookkeeping。即使如此,在反序列化时,大部分同步器类也只是仅将同步状态重置为初始值,这与内置锁的隐式策略一直 —— 总是反序列化到一个解锁状态。这相当于一个空操作,但仍必须显式地支持以便 ·final 字段能够反序列化。
4.1 公平调度的控制
即使它们基于 FIFO 队列,同步器也不一定是公平的。请注意,在基础的 acquire 算法(第 3.3 节)中,tryAcquire 检查是在排队之前执行的。因此,新的 acquire 线程可以“窃取”本该属于队列头部第一个线程通过同步器的机会。
可 闯入的FIFO 策略通常比其他技术提供更高的总吞吐量。当一个存在竞争的锁已经空闲,而下一个准备获取锁的线程正在解除阻塞的过程中,此时没有线程可以获取到这个锁,如果使用闯入策略,则可以减少这之间的时间。与此同时,这种策略还可以避免过多的、无效的竞争(只允许一个(第一个)排队的线程被唤醒,然后尝试 acquire 操作导致)。如果是短时间持有同步器的场景,创建同步器的开发人员在可以通过定义 tryAcquire ,在控制权返回之前重复调用自己若干次,来进一步凸显闯入效果。
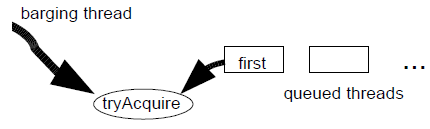
可闯入的 FIFO 同步器只有概率性的公平属性。在锁队列的头部一个解除了阻塞的线程拥有一次无偏向的机会来赢得与闯入线程之间的竞争,如果竞争失败,那么要么重新阻塞,要么进行重试。然而,如果闯入的线程到达的速度比队头的线程解除阻塞更快,俺么在队列中的第一个线程将会很难赢得竞争,以及于几乎总是要重新阻塞,并且它的后继节点也会一直保持阻塞。对于短暂持有的同步器来说,在队列中第一个线程被解除阻塞的期间,多处理器上很可能发生过多次闯入和 release。如下文所述,最终结果就是保持一个或多个线程的高速进展的同时,在一定概率是避免了饥饿的发生。
当需要更高的公平性需求时,实现起来也很简单。如果需要严格的公平性,程序员可以定义 tryAcquire 为:如果当前线程不是队列的头结点(可以通过 getFirstQueuedThread方法检查这一点,这是框架提供的为数不多的几个检测方法之一),则立即返回失败(返回 false)。
一种更快、不太严格的方法是,如果队列(暂时)为空,也允许 tryAcquire 成功。在这种情况下,遇到空队列的多个线程可能会争取第一个获得锁,这样,通常至少有一个线程是不需要放入队列的。所有支持 fair 模式的 j.u.c 同步器都采用这种策略。
尽管公平性设置在实践中很有用,当时它们并没有保障,因为 Java Language Specification 没有提供这样的调度保证。例如:即使是严格公平的同步器,如果一组线程永远不需要阻塞来达到相互等待,那么 JVM 也可以决定完全按照顺序方式运行它们。实际上,在单处理上,在抢占式上下文切换之前,这样的线程有可能是各自运行了一段时间。如果这样的线程正持有某个互斥锁,它将很快被切换回来,仅仅是为了释放其持有的锁,然后会继续阻塞,因为它知道有另一个线程需要这把锁,这更增加了同步器可用但没有线程能来获取直接的间隔。同步器公平性设置在多处理器上的影响可能会更大,因为在这种环境中会产生更多的交错,因此一个线程就会有更多的机会发现锁被另一个线程请求。
在高度竞争的情况下,当保护短暂持有的代码体时,尽管可能性能不佳,但公平锁仍然能有效地工作。例如,当公平锁保护的是相对长的代码体和/或具有相对较长的锁间(inter-lock)间隔时,在这种情况下,闯入只能带来很小的性能优势,但却可能会大大增加无限等待的风险。同步器框架将这些工程决策留给用户来确定。
4.2 同步器
下面是 j.u.c 包中同步器定义方式的概述:
ReentrantLock 类使用同步状态来保存锁(重复)持有的次数。当锁被一个线程获取时,ReentrantLock 也会记录下当前获得锁的线程标识,以便检查是否是重复获取,以及当前错误的线程试图进行解锁操作时检测是否存在非法状态异常。ReentrantLock 还是用了 AQS 提供的 ConditionObject,并向外暴露了其他监控和检查的方法。ReentrantLock 通过在内部声明的两个不同的 AQS 实现类(提供公平模式的那个回禁用 闯入 策略 )来实现可选的公平模式,在创建 ReentrantLock 实例的时候根据配置使用相应的 AQS 实现类。
ReentrantReadWriteLock 类使用同步状态的 16 位来保存写锁计数,剩余的 16 位保存读锁计数。WriteLock 在其他方面的结构与 ReentrantLock 相同。ReadLock 使用 acquireShared 方法来启用多个读线程。
Semaphore 类(计数信号量)使用同步状态来保存当前计数。它里面定义的 acquireShared 方法会减少计数,或当计数为非正值时阻塞线程;tryRelease 方法会增加计数,如果计数现在是正数,可能还要解除线程的阻塞。
CountDownLatch 类使用同步状态来表示计数。当它达到零时,所有 acquire 都通过。
FutureTask 类使用同步状态来表示未来的运行状态(初始化、运行、取消、完成)。设置或取消一个 FutureTask 时,会调用 AQS 的 release 操作;等待计算结果的线程解除阻塞是通过 AQS 的 acquire 操作。
SynchronousQueue 类(一种 CSP(Communication Sequential Processes)形式的传递)使用了内部的等待节点,这些节点可以用于协调生产者和消费者。同时,它使用 AQS 同步状态来控制当某个消费者消费前一项时,允许一个生产者继续生产,反之亦然。
j.u.c 包的用户当然可以为自定义的应用定义自己的同步器。例如,那些曾考虑到过的,但没有采纳进这个包的同步器包括提供 WIN32 事件风格的语义类,binary latches、集中管理的锁以及基于树的屏障。
5. 性能
尽管同步器框架除了互斥锁之外,还支持许多其他类型的同步方式,但锁的性能是最容易测量和比较的。即便如此,仍由许多不同的测量方法。这里的实验主要目的在于展示开销和吞吐量。
在每个测试中,所有线程都重复的更新一个伪随机数,该随机数由 nextRandom(int seed) 方法计算:
int t = (seed % 127773) * 16807 - (seed / 127773) * 2836;
return (t > 0) ? t : t + 0x7fffffff;
在每次迭代中,线程以概率 S 在一个互斥锁下更新共享的生成器,否则更新其自己局部的生成器,此时是不需要锁的。因此,锁的占用是短暂的,这就会导致线程在持有锁期间被抢占时的外界干扰降到了最小。这个函数的随机性主要为了两个目的:确定是否需要使用锁(这个生成器足以应付这里的需求),以及使用循环中的代码不可能被轻易的优化掉。
这里比较了四种锁:内置的,用的是 synchronized 块;互斥锁,使用一个简单的 Mutex 类,如第四节所示;可重入锁,用的是 ReentrantLock;以及公平锁,用的是 ReentrantLock 的公平模式。所有测试都运行在 J2SE1.5 JDK build46(大致与beta2相同)的 server 模式下。在收集测试数据之前,测试程序执行了 20 次无竞争运行,以消除预热效应。除了公平模式测试只运行了一百万次迭代,其他每个线程测试运行一千万次迭代。
该测试运行在四台 X86 机器和四台 UltraSparc 机器上。所有 X86 机器都运行的是 RedHat 基于 NPTL 2.4 内核和库的 Linux 系统。所有的 UltraSparc 机器都运行的是 Solaris-9。测试时所有系统的负载都很轻。根据该测试的特征,并不要求操作系统完全空闲。“4P” 这个名字反映出双核超线程的 Xeon 更像是 4 路处理器,而不是 2 路处理器。这里没有将测试数据规范化。如下所示,同步的相对开销与处理器的数量、类型、速度之间不具备简单的关系。
| 名字 | 处理器数量 | 类型 | 速度(Mhz) |
|---|---|---|---|
| 1P | 1 | Pentium3 | 900 |
| 2P | 2 | Pentium3 | 1400 |
| 2A | 2 | Athlon | 2000 |
| 4P | 2HT | Pentium4/Xeon | 2400 |
| 1U | 1 | UltraSparc2 | 650 |
| 4U | 4 | UltraSparc2 | 450 |
| 8U | 8 | UltraSparc3 | 750 |
| 24U | 24 | UltraSparc3 | 750 |
5.1 开销
通过只只运行一个线程,从 S=1 时的每次迭代时间减去 S=0 (访问共享内存的概率为零)时的每次迭代时间得到的。表 2 显示了在非竞争的场景下每次锁操作的开销(以纳秒为单位)。Metux 类最接近于框架的基本耗时,可重入锁的额外开销是记录当前所有者线程和错误检查时的耗时,对于公平锁来说还会包含开始时检查队列是否为空的耗时。
表 2 还显示了 tryAcquire 与内置锁的“快速路径(fast path)”的耗时对比。这里的差异主要反映了各种锁和机器中使用的不同的原子指令以及内存屏障的耗时。在多处理器上,这些指令常常是完全优于所有其他指令的。内置锁和同步器类之间的主要差别,显然是由于 Hotspot 锁使用 compareAndSet 锁定和解锁,而同步器的 acquire 操作使用了一次 compareAndSet,但 release 操作用的是一次 volatile 写(即,多处理器上的一次内存屏障以及所有处理器上的重排序限制)。每个锁的绝对和相对耗时因机器的不同而不同。
| 机器 | 内置 | 互斥 | 可重入 | 公平可重入 |
|---|---|---|---|---|
| 1P | 18 | 9 | 31 | 37 |
| 2P | 58 | 71 | 77 | 81 |
| 2A | 13 | 21 | 31 | 30 |
| 4P | 116 | 95 | 109 | 117 |
| 1U | 90 | 40 | 58 | 67 |
| 4U | 122 | 82 | 100 | 115 |
| 8U | 160 | 83 | 103 | 123 |
| 24U | 161 | 84 | 108 | 119 |
在另一个极端,表 3 显示了在 S=1 的情况下,运行 256 个并发线程时产生了大规模的锁竞争下每个锁的开销。在完全饱和的情况下,可闯入的 FIFO 锁比内置锁的开销少了一个数量级(相当于更大的吞吐量),比公平锁少了两个数量级。这证明了即使在极端争用的情况下,可闯入FIFO策略在保持线程进度方面的有效性。
表 3 也说明了即使在内部开销比较低的情况下,公平锁的性能也完全是由上下文切换的时间所决定的。列出的时间大致上都与各平台上线程阻塞和解除线程阻塞的时间成比例。
此外,后续增加的一个实验(仅使用机器 4P)显示,对于这里使用的非常短暂的锁,公平性设置对总体方差只有很小的影响。这里将线程终止时间的差异被记录为可变性的粗粒度度量。在机器 4P 上,公平锁的时间度量的标准差平均为 0.7%,可重入锁平均为 6.0%。作为对比,为模拟一个产时间持有锁的场景,测试中使每个线程在持有锁的情况下计算了 16K 次随机数。这时,总运行时间几乎是相同的(公平锁:9.79s,可重入锁:9.72s)。公平模式下的差异依然很小,标准差平均为 0.1%,而可重入锁上升到了平均 29.5%。
| 机器 | 内置 | 互斥 | 可重入 | 公平可重入 |
|---|---|---|---|---|
| 1P | 521 | 46 | 67 | 8327 |
| 2P | 930 | 108 | 132 | 14967 |
| 2A | 748 | 79 | 84 | 33910 |
| 4P | 1146 | 188 | 247 | 15328 |
| 1U | 879 | 153 | 177 | 41394 |
| 4U | 2590 | 347 | 368 | 30004 |
| 8U | 1274 | 157 | 174 | 31084 |
| 24U | 1983 | 160 | 182 | 32291 |
5.2 吞吐量
大多数同步器的使用范围在无竞争和饱和竞争这两个极端之间。这可以用实验在两个方面进行检查,通过修改固定数量线程的竞争概率,和/或通过向一组具有固定竞争概率的线程添加更多的线程。为了说明这些影响,测试运行在不同的竞争概率和不同的线程数目下,都用的是可重入锁。附图使用了一个 slowdown 度量标准:
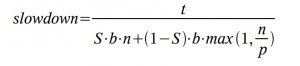
这里,t 是总运行时间,b 是一个线程在没有竞争或同步的情况下的基线时间,n 是线程的数量,p 是处理器的数量,S 是共享访问的比例。计算结果是实际执行时间与理想执行时间(通常是无法达到的)的比率,理想执行时间是通过使用 Amdahl's 定律对顺序和并行任务的混合计算得到。理想的时间模型是在没有任何同步开销的情况下,没有线程因为与其他线程冲突而阻塞。即便如此,在竞争非常少的情况下,一些测试结果显示,与理想情况相比,有些测试结果表现出了很小的速度增长,大概是由于基线和测试之间的优化、流水线等方面有着轻微的差别。
图中用以 2 为底的对数为比例进行了缩放。例如,值为 1 表示实际时间是理想时间的两倍,4 表示慢 16 倍。使用对数就不需要依赖一个随意的基线时间(这里是计算随机数的时间),因此,基于不同底数的计算结果表现出的趋势应该是类似的。这些测试使用的竞争概率从 1/128(标识为 “0.008”)到 1,以 2 的幂为步长,线程的数量从 1 到 1024,以 2 的幂的一半为步长。
在单处理器上(1P 和 1U),性能会随着竞争的增加而降低,但通常不会随着线程数量的增加而降低。多处理器在竞争的情况下,通常会遇到更糟糕的性能下降。根据多处理器相关的图表显示,开始出现的峰值处虽然只有几个线程的竞争,但相对性能通常却最差。这反映出了一个性能的 过渡区域,在这里闯入的线程和被唤醒的线程都准备获取锁,这会让它们频繁的迫使对方阻塞。在大部分时候,过渡区域后面会紧接着一个 平滑区域,因为此时几乎没有空闲的锁,所以会与单处理器上的顺序执行模式差不多;在多处理器上会较早进入平滑区域。例如,请注意,在处理器数量较少的机器上,满竞争(标记为 “1.000”)表现出相对较差的速度下降。
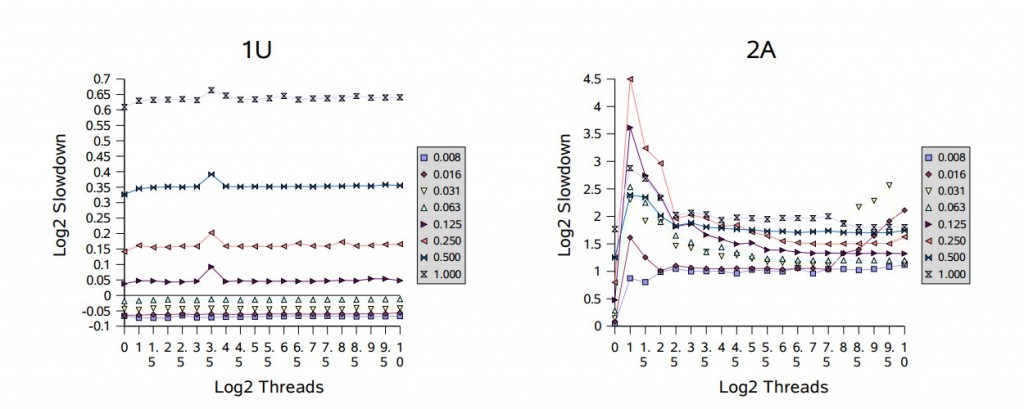
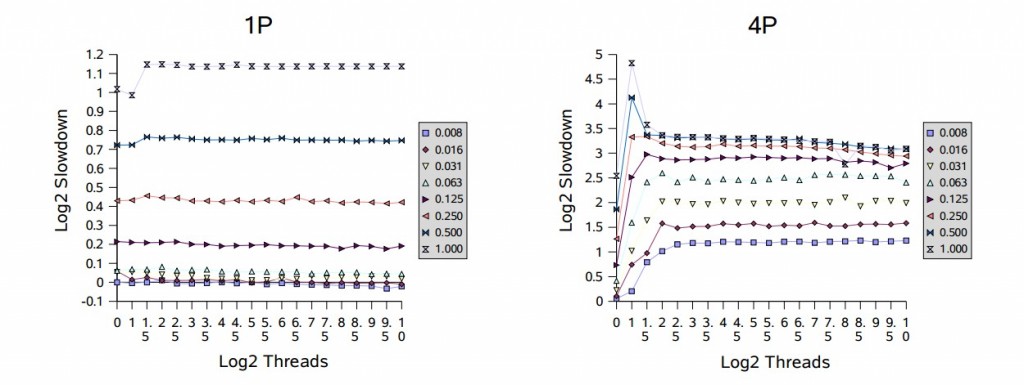
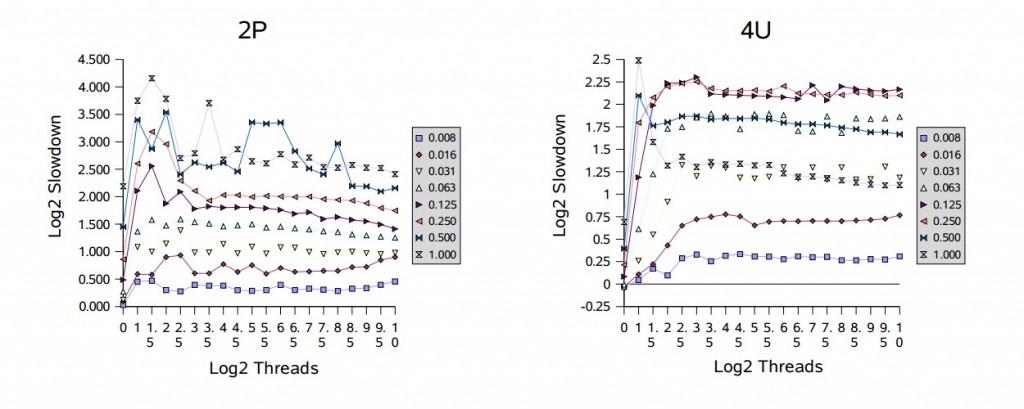
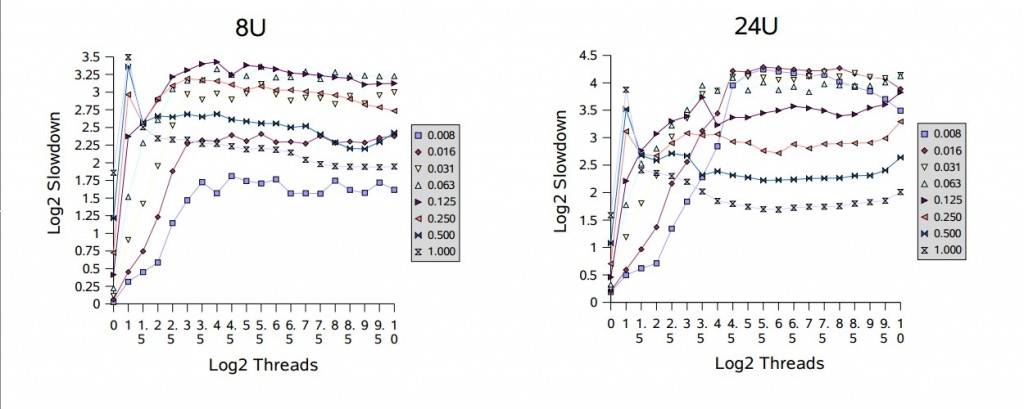
基于这些结果,进一步调整阻塞(park/unpark)以减少上下文切换和相关的开销,这会给本框架带来小但显著的提升。此外,在多处理上为短时间持有的但高竞争的锁采用某种形式的适应性自旋,可以避免这里看到的一些波动,这对同步器类有很大好处。虽然在跨不同上下文时适应性自旋很难很好的工作,但可以使用本框架为遇到这类使用配置的特定应用构建一个自定义形式的锁。
6. 结论
在撰写本文时,j.u.c同步器框架还太新,无法在实践中进行使用。因此在 J2SE 1.5 最终发布之前,它不太可能被广泛使用,而且他的设计、API 实现以及性能肯定还有无法预料的后果。但是,此时,这个框架明显能胜任其基本目标,即为创建新的同步器提供一个高效的基础。
7. 致谢
Thanks to Dave Dice for countless ideas and advice during the development of this framework, to Mark Moir and Michael Scott for urging consideration of CLH queues, to David Holmes for critiquing early versions of the code and API, to Victor Luchangco and Bill Scherer for reviewing previous incarnations of the source code, and to the other members of the JSR166 Expert Group (Joe Bowbeer, Josh Bloch, Brian Goetz, David Holmes, and Tim Peierls) as well as Bill Pugh, for helping with design and specifications and commenting on drafts of this paper. Portions of this work were made possible by a DARPA PCES grant, NSF grant EIA-0080206 (for access to the 24way Sparc) and a Sun Collaborative Research Grant.
8. 引用
- [1] Agesen, O., D. Detlefs, A. Garthwaite, R. Knippel, Y. S.Ramakrishna, and D. White. An Efficient Meta-lock for Implementing Ubiquitous Synchronization. ACM OOPSLA Proceedings, 1999.
- [2] Andrews, G. Concurrent Programming. Wiley, 1991.
- [3] Bacon, D. Thin Locks: Featherweight Synchronization for Java. ACM PLDI Proceedings, 1998.
- [4] Buhr, P. M. Fortier, and M. Coffin. Monitor Classification,ACM Computing Surveys, March 1995.
- [5] Craig, T. S. Building FIFO and priority-queueing spin locks from atomic swap. Technical Report TR 93-02-02,Department of Computer Science, University of Washington, Feb. 1993.
- [6] Gamma, E., R. Helm, R. Johnson, and J. Vlissides. Design Patterns, Addison Wesley, 1996.
- [7] Holmes, D. Synchronisation Rings, PhD Thesis, Macquarie University, 1999.
- [8] Magnussen, P., A. Landin, and E. Hagersten. Queue locks on cache coherent multiprocessors. 8th Intl. Parallel Processing Symposium, Cancun, Mexico, Apr. 1994.
- [9] Mellor-Crummey, J.M., and M. L. Scott. Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors. ACM Trans. on Computer Systems,February 1991
- [10] M. L. Scott and W N. Scherer III. Scalable Queue-Based Spin Locks with Timeout. 8th ACM Symp. on Principles and Practice of Parallel Programming, Snowbird, UT, June 2001.
- [11] Sun Microsystems. Multithreading in the Solaris Operating Environment. White paper available at http://wwws.sun.com/software/solaris/whitepapers.html 2002.
- [12] Zhang, H., S. Liang, and L. Bak. Monitor Conversion in a Multithreaded Computer System. United States Patent 6,691,304. 2004.